python爬虫库有哪些?

提起Python,很多人第一印象就是——Python是做爬虫的。Python爬虫给人留下了深刻的印象,下面我们了解下python爬虫库有哪些?
1、Python Request
Requests继承了urllib的特性,与urllib相比,Requests更加方便,可以节约我们大量的工作,建议爬虫使用Requests库。requests提供了get、post、put、delete、head、options操作方式,具体如下:
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-09-07
import requests
requests.get(url)
requests.post(url)
requests.put(url)
requests.delete(url)
requests.head(url)
requests.options(url)
2、Python Urllib
在Python2.x中我们可以通过urllib 或者urllib2 进行网页抓取,但是再Python3.x 移除了urllib2。只能通过urllib进行操作。urlib简单操作实例如下:
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-09-07
import urllib.request
# 网站是https访问的需要引入ssl模块
import ssl
# 导入ssl时关闭证书验证
ssl._create_default_https_context = ssl._create_unverified_context
response = urllib.request.urlopen('https://www.lidihuo.com/python/spider-test.html')
print(response.read().decode('utf-8'))
3、Python aiohttp
什么是 aiohttp?一个异步的 HTTP 客户端\服务端框架,基于 asyncio 的异步模块。可用于实现异步爬虫,更快于 requests 的同步爬虫。简单操作实例如下:
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-09-07
import requests
from datetime import datetime
def fetch(url):
r = requests.get(url)
print(r.text)
start = datetime.now()
for i in range(30):
fetch('https://www.lidihuo.com/python/spider-test.html')
end = datetime.now()
print("requests版爬虫花费时间为:")
print(end - start)
4、Python Selenium
Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器。Selenium安装可以通过以下命令:
5、Python asks
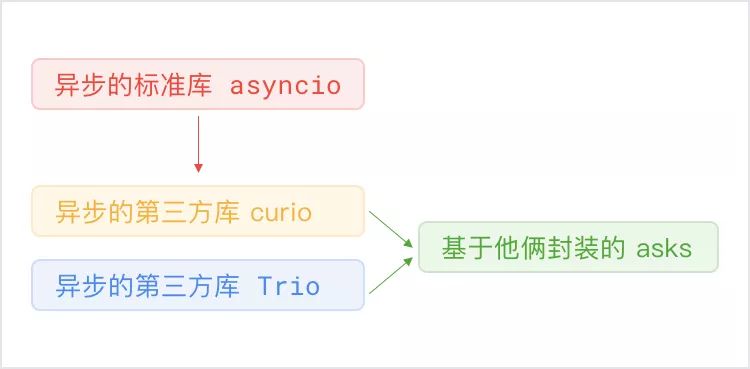
Python 自带一个异步的标准库 asyncio,但是这个库很多人觉得不好用,甚至是 Flask 库的作者公开抱怨自己花了好长时间才理解这玩意,于是就有好事者撇开它造了两个库叫做 curio 和 trio,而这里的 ask 则是封装了 curio 和 trio 的一个 http 请求库。
用起来和 Requests 90%相似,新手也可以很快上手。