Python Urllib库
Python Urllib库详细教程
urllib
在Python2.x中我们可以通过urllib 或者urllib2 进行网页抓取,但是再Python3.x 移除了urllib2。只能通过urllib进行操作
import urllib.request
# 网站是https访问的需要引入ssl模块
import ssl
# 导入ssl时关闭证书验证
ssl._create_default_https_context = ssl._create_unverified_context
response = urllib.request.urlopen('https://www.lidihuo.com/python/spider-test.html')
print(response.read().decode('utf-8'))
运行结果:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>python spider </title>
</head>
<body>
Hello,I am lidihuo
Welcome to Python spider
</body>
</html>
带参数的urllib
import urllib.request
# 网站是https访问的需要引入ssl模块
import ssl
# 导入ssl时关闭证书验证
ssl._create_default_https_context = ssl._create_unverified_context
url = 'https://www.lidihuo.com/python/spider-test.html'
url = url + '?' + key + '=' + value1 + '&' + key2 + '=' + value2
response = urllib.request.urlopen(url)
# print(response.read().decode('utf-8'))
urllib.request定义了以下函数:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
参数说明:
url: 网页地址,打开url可以是字符串或者是Request对象。
data: 一个定义了向服务器所发送额外数据的对象,或者如果没有必要数据的话,就是None值。
timeout: 参数指定阻止诸如连接尝试等操作的超时时间(以秒为单位)
context: 描述各种SSL选项的ssl.SSLContext实例。
cafile/capath: 为HTTPS请求指定一组可信的CA证书。
返回值:
该函数总是返回一个可以作为context manager使用的对象,并且具有方法,例如:
geturl(): 返回检索的资源的URL,通常用于确定是否遵循重定向;
info(): 以email.message_from_string()实例的形式返回页面的元信息(如headers)(可快速参考HTTP Headers);
getcode(): 返回响应的HTTP状态码。
对于HTTP和HTTPS URL,此函数返回稍微修改的http.client.HTTPResponse对象。
除上述三种新方法之外,msg属性还包含与reason属性(服务器返回的原因短语)相同的信息,而不是HTTPResponse文档中指定的响应标头。
对于由传统URLopener和FancyURLopener类明确处理的FTP,文件和数据URL和请求,此函数返回一个urllib.response.addinfourl对象。
在协议错误上引发URLError。
请注意,如果没有处理请求的handler,则可能返回None(尽管默认安装的全局OpenerDirector使用UnknownHandler来确保永不发生这种情况)。
另外,如果检测到代理设置(例如,如果设置了诸如http_proxy的* _proxy环境变量),则默认安装ProxyHandler,并确保通过代理处理请求。
来自Python 2.6及更早版本的遗留urllib.urlopen函数已停止使用; urllib.request.urlopen()对应于旧的urllib2.urlopen。
通过使用ProxyHandler对象可以获得通过将字典参数传递给urllib.urlopen完成的代理处理。
POST/GET请求
上面的程序演示了最基本的网页抓取,不过,现在大多数网站都是动态网页,需要你动态地传递参数给它,它做出对应的响应。POST和GET请求最重要的区别是GET方式是直接以链接形式访问,链接中包含了所有的参数,POST则不会在网址上显示所有的参数。
POST方式:
下面演示POST请求方式
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-19
#post 请求
import urllib.request
import urllib.parse
base_url="你的请求网址"
# 你请求网址的参数
data={
"name":"www.lidihuo.com",
"pass":"xxxx"
}
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE"}
postdata=urllib.parse.urlencode(data).encode('utf-8')
req=urllib.request.Request(url=base_url,headers=headers,data=postdata,method='POST')
response=urllib.request.urlopen(req)
html=response.read()
# html=response.read().decode('utf-8') #这里讲解一下decode()是把bytes转化解码为了 str ,
print(html)
上面例子中的base_url和data参数需根据网址自行设置,下面利用urllib的urlencode方法将字典编码,命名为data,构建request时传入两个参数,url和data,运行程序,返回的便是POST后呈现的页面内容。
GET方式请求:
GET方式我们可以直接把参数写到网址上面,直接构建一个带参数的URL出来即可。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-19
from urllib import parse, request
import random
url = 'https://www.lidihuo.com/python/spider-test.html'
keyvalue = 'url参数'
encoded_wd = parse.urlencode(wd)
new_url = url + '?' + encoded_wd
req = request.Request(url)
# 为了防止被网站封ip,模仿浏览器访问网站
ua_list = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
# 在User-Agent列表里随机选择一个User-Agent ;从序列中随机选取一个元素
user_agent = random.choice(ua_list)
req.add_header('User-Agent', user_agent)
response = request.urlopen(req)
print(response.read().decode('utf-8'))
PUT/DELETE请求
http协议有六种请求方法,get,head,put,delete,post,options,我们有时候需要用到PUT方式或者DELETE方式请求。
PUT:这个方法比较少见。HTML表单也不支持这个。本质上来讲,
PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-20
import urllib.request
DATA=b'some data'
req = urllib.request.Request(url='网址', data='参数',method='PUT/DELETE')
f = urllib.request.urlopen(req)
print(f.status)
print(f.reason)
设置Headers
打开我们的浏览器,调试浏览器F12,能看到浏览器很多header信息,如下图所示:
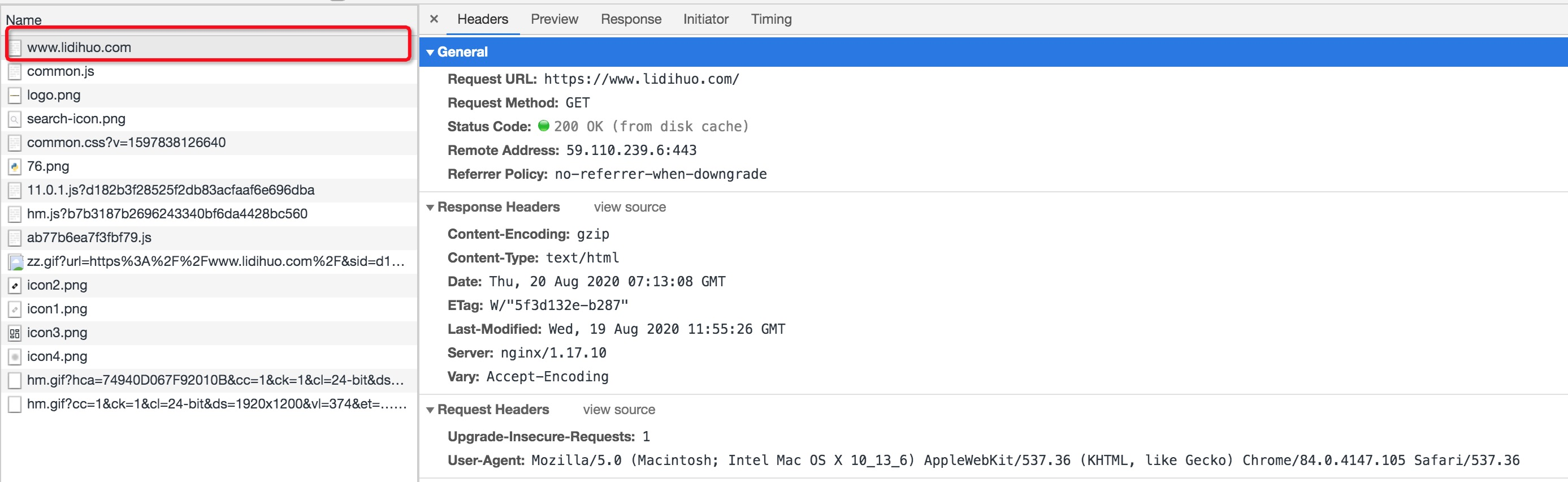 User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求。
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用。
application/json : 在 JSON RPC 调用时使用。
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用。
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求。
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用。
application/json : 在 JSON RPC 调用时使用。
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用。
其中,agent就是请求的身份,user-agent能够使服务器识别出用户的操作系统及版本、cpu类型、浏览器类型和版本。很多网站会设置user-agent白名单,只有在白名单范围内的请求才能正常访问。所以在我们的爬虫代码中需要设置user-agent伪装成一个浏览器请求。有时候服务器还可能会校验Referer,所以还可能需要设置Referer(用来表示此时的请求是从哪个页面链接过来的)。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-20
# 伪装浏览器的爬虫
from urllib import request
import re
import ssl
url="https://www.lidihuo.com/python/spider-test.html"
# 导入ssl时关闭证书验证
ssl._create_default_https_context = ssl._create_unverified_context
# 构造请求头信息
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
req=request.Request(url,headers=header)
# 发送请求.获取响应信息
reponse=request.urlopen(req).read().decode() #解码---(编码encode())
pat=r"(.*?)"
data=re.findall(pat,reponse)
#由于data返回的是列表形式的数据用data[0]直接取值
print(data[0])
运行结果:
Proxy(代理)的设置
动态设置代理,就是事先准备一堆User-Agent.每次发送请求时就从中间随机选取一个,采用 random随机模块的choice方法随机选择User-Agent,这样每次请求都会从中选择,请求很频繁的话就多找几个user-agent,具体如下:
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-20
def load_page(url, form_data):
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
user_agent = random.choice(USER_AGENTS)
headers = {
'User-Agent':user_agent
}
同时还可以设置一些代理服务器,每隔一段时间换一个代理IP,就算代理IP被禁止,依然可以换个IP继续爬取。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-20
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy = '127.0.0.1:8088'
# 参数是字典,键名是协议类型,健值是代理
proxy_handler = ProxyHandler({
'http': 'http://' + proxy,
'https': 'https://' + proxy
})
# Opener已经设置好代理了
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.lidihuo.com/python/spider-test.html')
# 运行结果是一个JSON
print(response.read().decode('utf-8'))
except URLError as e:
上面的代理可以自己本地搭建,还可以购买一些代理服务器
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-20
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
# 加入代理认证的用户名和密码
proxy = '用户名:密码@ip:port'
proxy_handler = ProxyHandler({
'http': 'http://' + proxy,
'https': 'https://' + proxy
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.lidihuo.com/python/spider-test.html')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)

