MongoDB Shell集合方法
以下是在不同情况下使用的MongoDB收集方法。
#1: db.collection .aggregate(pipeline, option)
聚集方法为集合/表或视图中的数据计算质量值。
pipeline: 是海量数据操作或阶段的数组。它可以接受管道作为单独的参数,而不是作为数组中的元素。如果未将管道指定为数组,则不会指定第二个参数。
option: 传递了聚合命令的文档。仅当您将管道指定为数组时,该选项才可用。
命令字段:
| 字段 |
类型 |
说明 |
| explain |
boolean |
说明字段指定返回有关管道处理的信息。 |
| allowDiskUse |
boolean |
"允许使用磁盘"字段使您可以写入临时文件。 |
| cursor |
document |
使用此字段指定光标的初始批处理大小。该字段内的值是带有batchSize字段的文档。 |
| maxTimeMS |
非负整数 |
使用此字段指定对光标进行处理操作的时间限制。 |
| bypassDocument |
Validation |
boolean可以使用此字段指定$out或$merge聚合阶段。它允许聚合收集方法在操作过程中绕过文档验证。 |
| readConcern |
document |
您可以使用此字段指定阅读关注级别。 |
| collation |
document |
排序规则字段指定用于字符串比较的特定于语言的规则。 |
示例
示例使用包含以下文档的集合库:
{ _id: 1, book_id: "Java", ord_date: ISODate("2012-11-02T17:04:11.102Z"), status: "A", amount: 50 }
{ _id: 0, book_id: "MongoDB", ord_date: ISODate("2013-10-01T17:04:11.102Z"), status: "A", amount: 100 }
{ _id: 0.01, book_id: "DBMS", ord_date: ISODate("2013-10-12T17:04:11.102Z"), status: "D", amount: 25 }
{ _id: 2, book_id: "Python", ord_date: ISODate("2013-10-11T17:04:11.102Z"), status: "D", amount: 125 }
{ _id: 0.02, book_id: "SQL", ord_date: ISODate("2013-11-12T17:04:11.102Z"), status: "A", amount: 25 }
计算总和
db.library.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$book_id", total: { $count: "$amount" } } },
{ $sort: { total: -1 } }
])
输出:

指定排序规则
db.library.aggregate(
[ { $match: { status: "A" } }, { $group: { _id: "$ord_date", count: { $count: 1 } } } ],
{ library: { locale: "fr", strength: 1 } } );
#2 db.collection.bulkWrite()
bulkWrite()方法按照执行控制的顺序执行多个写入操作。写入操作数组由该操作执行。默认情况下,操作以特定顺序执行。
语法:
db.collection.bulkWrite(
[ <op. 1>, <op. 2>, .. ],
{
writeConcern : <document>,
ordered: <boolean>
}
)
输出:
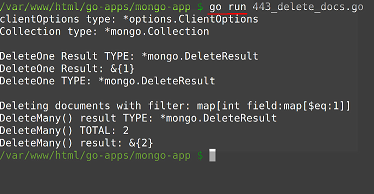
执行操作
insertOne: : 它仅将一个文档插入集合中。
db.collection.bulkWrite( [
{ insertOne : { "document" : <document> } }
] )

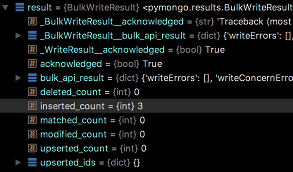
更新一个: 只有一个与集合中的过滤器匹配的文档。
db.collection.bulkWrite( [
{ updateOne :
{
"filter": <document>,
"update": <document or pipeline>,
"upsert": <boolean>,
"collation": <document>,
"arrayFilters": [ <filterdocument1>, ... ],
"hint": <document|string>
}
}
] )
输出:
多次更新: : 它将更新集合中所有与过滤条件匹配的文档。
db.collection.bulkWrite( [
{ updateMany :{
"filter" : <doc.>,
"update" : <document or pipeline>,
"upsert" : <Boolean>,
"collation": <document>,
"arrayFilters": [ <filterdocument1>, ... ],
"hint": <document|string> // Available starting in 4.2.1
}
}
] )
replaceOne: : 它将替换集合中与过滤器匹配的单个文档。
db.collection.bulkWrite([
{ replaceOne :
{
"filter" : <doc.>,
"replacement" : <doc.>,
"upsert" : <boolean>,
"collation": <document>,
"hint": <document|string>
}
}
] )
#3. db.collection.count(query,option)
count()方法返回与该集合的find方法查询匹配的文档数。视图。
示例:
我们将使用以下操作对lidihuo集合中的所有文档进行计数:
现在,我们将计算lidihuo集合中与查询匹配的所有文档,其中tut_dt字段大于新日期('01/01/2015')
db.lidihuo.count( { tut_dt: { $gt: new Date('01/01/2015') } } )
输出:

#4、 Db.collection.countDocuments(query,options)
countDocument()方法返回与集合或视图的查询相匹配的文档数。它不会使用元数据来返回计数。
语法:
db.collection.countDocuments( <query>, <options> )
示例:
下面的示例将计算lidihuo集合中所有文档的数量。
db.lidihuo.countDocuments({})
现在,我们将计算lidihuo集合中与查询匹配的所有文档,其中tut_dt字段大于新日期('01/01/2015')
db.lidihuo.countDocuments( { tut_dt: { $gt: new Date('01/01/2015') } } )
#5、 db.collection.estimatedDocumentCount()
estimateddocumentCount()方法对集合或视图中的所有文档进行计数。此方法包装count命令。
语法:
db.collection.estimatedDocumentCount( <options> )
示例
下面的示例将检索 lidihuo中所有文档的计数集合:
db.lidihuo.estimatedDocumentCount({})
#6、 db.collection.createIndex()
它可以在集合上创建索引
语法:
db.collection.createIndex(keys, options)
键: 对于字段的升序索引,我们需要指定值1,对于降序索引,我们需要指定值-1、
示例
下面的示例在tut_Date字段上创建一个升序索引。
db.collection.createIndex( { tut_Date: 1 } )
下面的示例显示在tut_Date字段和tut_code字段上创建的复合索引。
db.collection.createIndex( { tut_Date: 1, tut_code: -1 } )
下面的示例将创建一个名为category_tutorial的索引。该示例使用排序规则创建索引,该排序规则指定语言环境fr和比较强度。
db.collection.createIndex(
{ category: 1 },
{ name: "category_tutorial", collation: { locale: "fr", strength: 2 } }
)
#7、 db.collection.createIndexes()
createIndexes()方法在集合上创建一个或多个索引。
语法:
db.collection.createIndexes( [keyPatterns, ]options)
Keypatterns : 这是一个包含索引特定文档的数组。所有文档都有字段-值对。对于字段的升序索引,我们需要指定值1,对于降序索引,我们需要指定值-1
示例
在以下示例中,我们考虑了一个员工集合,其中包含类似于以下内容的文档:
{
location: {
type: "Point",
coordinates: [-73.8577, 40.8447]
},
name: "Employee",
company: "Amazon",
borough: "CA",
}
输出:

现在,下面的示例在产品集合上创建两个索引:
在制造商字段上的索引按升序排列。
类别字段上的索引按升序排列。
上述索引使用归类,将基本fr和比较强度指定为2、
db.products.createIndexes( [ { "manufacturer": 1}, { "category": 1 } ],
{ collation: { locale: "fr", strength: 2 } })
#8、 db.collection.dataSize()
数据大小方法对collStats(即db.collection.stats())命令的输出进行了覆盖。
#9、 db.collection.deleteOne()
deleteOne()方法从集合中删除一个文档。它替换了与过滤器相似的第一个文档。您需要使用与唯一索引(例如id)相关的字段,以实现完美删除。
语法:
db.collection.deleteOne(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
示例
订单集合包含具有以下结构的文档:
{
_id: objectId("563237a41a4d6859da"),
book: "",
qty: 2,
type: "buy-limit",
limit: 10,
creationts: ISODate("2015-11-01T2:30:15Z"),
expiryts: ISODate("2015-11-01T2:35:15Z"),
client: "lidihuo"
}
以下操作删除带有_id的订单: objectId("563237a41a4d6858 2da"):
try {
db.orders.deleteOne( { "_id" : objectId("563237a41a4d68582da") } );
} catch (e) {
print(e);
}
输出: