Solr 索引
Apache Solr索引
索引是以系统的方式管理文档或其他实体。为了在文档中定位信息,我们使用索引。
索引可用于收集、解析和存储文档。
当我们查找所需文档时,它可用于提高搜索查询的速度和性能。
Solr 索引过程概述
Apache Solr 中的索引过程分为三个基本任务:
将文档从其原生格式(例如 XML 或 JSON)转换为 Solr 支持的格式。
使用多个定义良好的 Solr 接口之一添加文档,例如 HTTP POST。
Apache Solr 可以配置为在编制索引时对文档中的文本应用转换。
下图提供了在 Solr 中索引文档的三个必要步骤的高级概述。
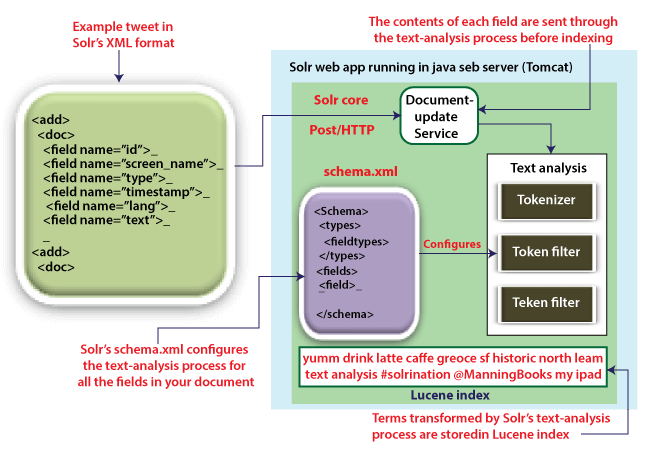
Solr 支持我们文档的不同索引格式,包括 JSON、XML 和 CSV。在上图中,我们选择了 XML,因为 XML 的自描述格式使其易于适应和理解。以下是示例,我们的推文使用 Solr XML 格式时的外观。
<add>
<doc>
<field name="id">1</field>
<field name="screen_name">@thelabdude</field>
<field name="type">post</field>
<field name="timestamp">2012-05-22T09:30:22Z</field>
<field name="lang">en</field>
<field name="user_id">99991234567890</field>
<field name="favorites_count">10</field>
<field name="text">#Yummm :) Drinking Cappuccino
Grecco in SF?s historic North Beach... Learning text
analysis with #SolrInAction by @lidihuo on my i-Phone</field>
</doc>
</add>
如您所见,每个字段以 XML 格式显示,语法简单明了;我们只为所有字段定义了字段名称和值。我们没有注意到有关文本或文件类型分析的任何内容。这是因为我们在上图所示的 schema.xml 文档中定义了如何分析字段。众所周知,Solr 为其所有核心服务提供了一个基于 HTTP 的基本接口,包括文档更新服务用于添加和更新文档。在图的左上角,我们描述了使用 HTTP POST 将推文示例的 XML 发送到文档中的更新服务索尔。此外,我们将在本教程后面看到如何添加特定的文档类型,例如 JSON、CSV 和 XML。我们现在将了解可用于验证文档中所有字段内容的文档更新服务,然后调用文本分析过程。分析完所有字段后,生成的文本将添加到索引中,使文档可用于搜索。
schema.xml 文件定义任何文档的字段和字段类型。对于任何简单的应用程序,可能需要搜索字段及其类型。不过,它可用于对您的架构进行一些预先规划。
设计您的架构
在我们的示例中,搜索的微博应用程序将直接潜入并定义我们想要索引的文档。实际上,对于实际应用程序而言,此过程并不总是显而易见的,因此它有助于进行一些预先设计和规划工作。现在,我们将了解搜索应用程序的基本设计注意事项。具体来说,我们将学习回答关于我们的搜索软件的给定关键问题:
我们索引中的文档是什么?
如何唯一标识所有文档。
用户通常搜索我们文档中的哪些字段?
应该在搜索结果中向用户显示哪些字段?
让我们确定搜索应用程序中文档的适当粒度,这会影响您回答其他问题的方式。
使用 Post 命令添加文档
Solr 的 bin 目录里面,有一个 post 命令。我们可以在 Solr 中索引各种格式的文件,例如 CSV、JSON 和 XML。
我们可以浏览 Solr 的 bin 目录并运行 post 命令的-h 选项,如下所示代码块。
$ cd $SOLR_HOME
$ ./post-h
当我们执行上面的命令时,我们会得到一个post命令的选项列表,如下图。
Usage: post-c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post ?help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or-port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
示例
让我们以一个名为 sample.csv 的文件为例,其中包含给定的内容(在 bin 目录中)。
| 学生证 |
名字 |
电话 |
城市 |
| 001 |
Olivia |
+148022337 |
California |
| 002 |
Emma |
+148022338 |
Hawaii |
| 003 |
Sophia |
+148022339 |
Florida |
| 004 |
Emily |
+148022330 |
Texas |
| 005 |
Harper |
+148022336 |
Kansas |
| 006 |
Scarlett |
+148022335 |
Kentucky |
上面的数据表包含个人详细信息,如学生 ID、名字、电话和城市名称。下面给出了数据文件的 CSV 文件。在这里,我们必须注意,您需要提及架构,记录其第一行。
| id |
名字 |
电话号码 |
位置 |
| 001 |
Olivia |
+848022337 |
Michigan |
| 002 |
Emma |
+848022338 |
Minnesota |
| 003 |
Sophia |
+848022339 |
North Carolina |
| 004 |
Emily |
+848022330 |
Ohio |
| 005 |
Harper |
+848022336 |
Oregon |
| 006 |
Scarlett |
+848022335 |
Pennsylvania |
您可以使用下面给出的 post 命令在名为"sample_Solr"的核心中索引这些数据:
[Hadoop@localhost bin]$ ./post-c Solr_sample sample.csv
当我们执行上述命令时,给定的文档将在指定的核心下建立索引并生成给定的输出。
/home/Hadoop/java/bin/java-classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar-Dauto = yes-Dc = Solr_sample-Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228
使用给定的 URL 转到 Solr Web 用户界面的主页:
http://localhost:8983/
选择核心主页上的 Solr_sample。不做任何修改,点击页面底部的 ExecuteQuery 按钮。
当我们执行查询时,我们可以观察到默认格式(JSON) 索引的 CSV 文档的数据,如下面的屏幕截图所示。
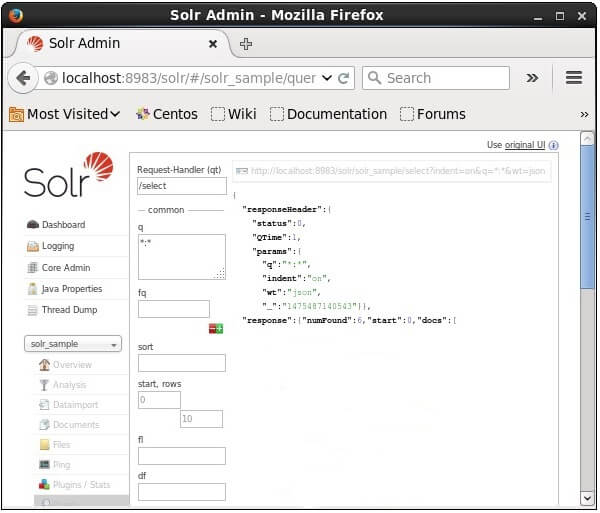
注意: 注意-同样,我们可以索引不同的文件格式,如 XML、CSV、JSON 等。
使用 Solr Web 界面添加文档
您还可以使用 Solr 提供的 Web 界面索引文档。让我们看看如何索引以下 JSON 文档。
[
{
"id" : "001",
"name" : "Emma",
"age" : 25,
"Designation" : "Executive",
"Location" : "Texas",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "New York",
},
{
"id" : "003",
"name" : "John",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "California",
}
]
第 1 步: 使用给定的 URL 转到 Solr Web 界面-http://localhost:8983/
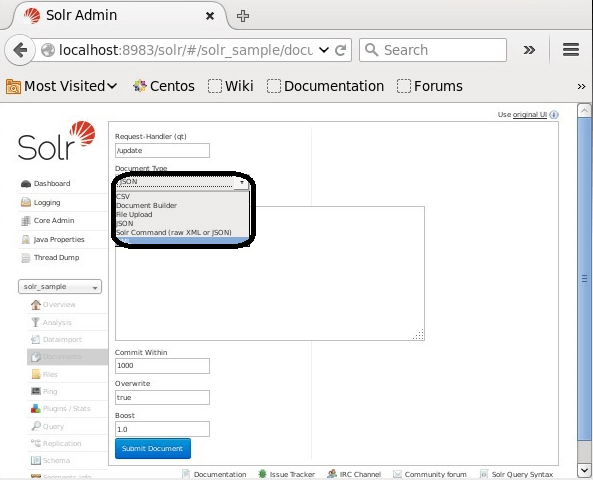
第 2 步: 选择核心"Solr_sample"。如下图所示,Request Handler、Common Within、Overwrite 和Boost 字段的值分别为/update、1000、true 和1.0。
步骤3: 最后,从 CSV、XML、JSON 等中选择您想要的文档格式。在文本区域下输入您想要索引的文档,然后单击"提交文档"按钮,如下面的屏幕截图所示。

使用 Java 客户端 API 添加文档
如您所见,以下是将文档添加到 Solr 索引的 Java 源代码。使用名称 AddDocument.java 保存此程序。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Prepare the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Prepare the Solr doc.
SolrInputDocument doc = new SolrInputDocument();
//Add fields to the doc.
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Add the doc. to Solr
Solr.add(doc);
//Save the changes
Solr.commit();
System.out.println("Documents added");
}
}
以上代码在终端执行以下命令即可编译-
$ javac AddingDocument
$ java AddingDocument
当我们运行上述命令时,我们将在显示器上收到以下输出。
输出:
已添加文档。

