Weka 启动资源管理器
在本章中,让我们看看资源管理器为处理大数据而提供的各种功能。
当您点击
Applications 选择器中的
Explorer 按钮时,它会打开以下屏幕-
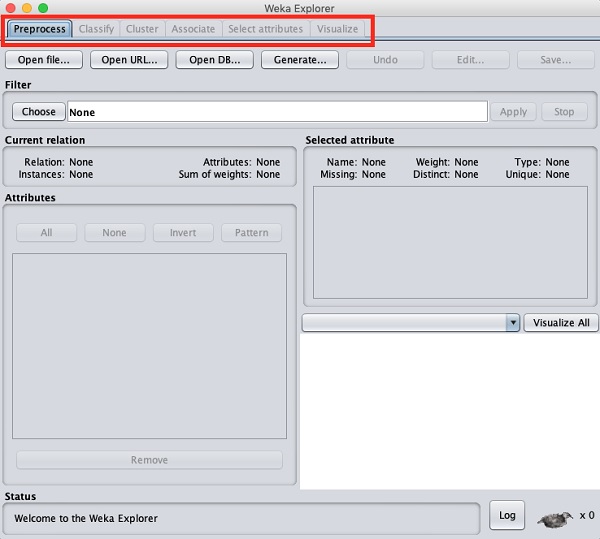
在顶部,您会看到此处列出的几个选项卡-
预处理
分类
集群
同事
选择属性
可视化
在这些选项卡下,有几个预先实现的机器学习算法。现在让我们详细研究一下它们。
预处理选项卡
最初当您打开资源管理器时,仅启用了
预处理 选项卡。机器学习的第一步是预处理数据。因此,在
预处理选项中,您将选择数据文件,对其进行处理并使其适合应用各种机器学习算法。
分类标签
分类 选项卡为您提供了多种用于数据分类的机器学习算法。举几个例子,您可能会应用诸如线性回归、逻辑回归、支持向量机、决策树、RandomTree、RandomForest、NaiveBayes 等算法。该列表非常详尽,提供了有监督和无监督的机器学习算法。
集群标签
在
Cluster 选项卡下,提供了多种聚类算法-例如 SimpleKMeans、FilteredClusterer、HierarchicalClusterer 等。
关联标签
在
Associate 标签下,您会找到 Apriori、FilteredAssociator 和 FPGrowth。
选择属性选项卡
Select Attributes 允许您基于多种算法(例如 ClassifierSubsetEval、PrincipalComponents 等)进行特征选择。
可视化标签
最后,
Visualize 选项允许您将处理过的数据可视化以进行分析。
如您所见,WEKA 提供了多种现成的算法来测试和构建您的机器学习应用程序。要有效地使用 WEKA,您必须充分了解这些算法、它们的工作原理、在什么情况下选择哪一个、在处理后的输出中寻找什么等等。总之,你穆您必须在机器学习方面有扎实的基础,才能有效地使用 WEKA 构建您的应用。
在接下来的章节中,您将深入研究资源管理器中的每个选项卡。

