
| 组件和描述 |
|
Client
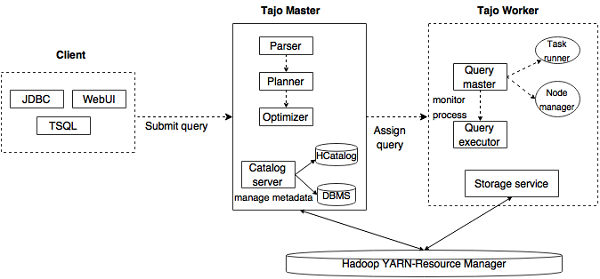
Client 将 SQL 语句提交给 Tajo Master 得到结果。
|
|
Master
Master 是主守护进程。它负责查询规划,是工人的协调员。
|
|
Catalog server
维护表和索引描述。它嵌入在主守护进程中。目录服务器使用 Apache Derby 作为存储层,通过 JDBC 客户端连接。
|
|
Worker
主节点将任务分配给工作节点。 TajoWorker 处理数据。随着 TajoWorker 数量的增加,处理能力也呈线性增长。
|
|
Query Master
Tajo Master 将查询分配给 Query Master。 Query Master 负责控制分布式执行计划。它启动 TaskRunner 并将任务安排到 TaskRunner。 Query Master的主要作用是监控正在运行的任务,并上报给Master节点。
|
|
Node Managers
管理工作节点的资源。它决定向节点分配请求。
|
|
TaskRunner
充当本地查询执行引擎。它用于运行和监控查询过程。 TaskRunner 一次处理一个任务。
它具有以下三个主要属性-
逻辑计划-创建任务的执行块。 片段-输入路径、偏移范围和架构。 获取 URI |
|
Query Executor
用于执行查询。
|
|
Storage service
将底层数据存储连接到 Tajo。
|
