Java中HashSet和HashMap类之间的区别
Java中
HashMap</strong>和
HashSet 是最受欢迎的Collection类。两者都用于数据结构。下表描述了HashMap和HashSet之间的区别:
| HashMap</td>
| HashSet |
| Java HashMap是基于哈希表的Map接口实现。 |
HashSet是一个Set。它创建一个使用哈希表进行存储的集合。 |
| HashMap实现了 Map,Cloneable和Serializable 接口。 |
HashSet实现 Set,Cloneable,Serializable,Iterable 和 Collection 接口。 |
| 在HashMap中,我们存储一个键值对。它维护键和值的映射。 |
在HashSet中,我们存储对象。 |
| 不允许重复键,但允许重复值。 |
它不允许重复值。 |
| 它可以包含一个单个null键和多个null值。 |
它可以包含单个空值。 |
| HashMap使用 put()方法在HashMap中添加元素。 |
HashSet使用 add()方法在HashSet中添加元素。 |
| HashMap比HashSet更快/,因为值与唯一键相关联。 |
HashSet比HashMap<strong>慢,因为成员对象用于计算哈希码值,这对于两个对象可以相同。 |
| 在添加操作期间仅创建一个对象。 |
在放置操作期间创建了两个对象,一个用于键,一个用于 value 。 |
| HashMap在内部使用散列来存储对象。 |
HashSet在内部使用 HashMap</strong>对象存储对象。 |
| 当我们不保持唯一性时总是喜欢。 |
当我们需要保持数据的唯一性时使用。 |
| {a-> 4,b-> 9,c-> 5} ,其中 a,b,c 是键和 4、9、5 是与键关联的值。 |
{6,43,2,90,4} 表示集合。 |
让我们通过程序理解它们之间的区别。
HashMap示例
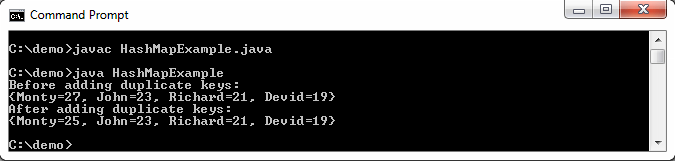
在下面的示例中,当我们添加具有相同元素的重复元素时键和其他值,则该键的先前值将被新值替换。
当我们添加具有相同键和相同值的重复元素时,键-值对不会存储第二次。
import java.util.*;
public class HashMapExample
{
public static void main(String args[])
{
HashMap<String, Integer> hm= new HashMap<String, Integer>();
hm.put("John", 23);
hm.put("Monty", 27 );
hm.put("Richard", 21);
hm.put("Devid", 19);
System.out.println("Before adding duplicate keys: ");
System.out.println(hm);
hm.put("Monty", 25);
hm.put("Devid", 19);
System.out.println("After adding duplicate keys: ");
System.out.println(hm);
}
}
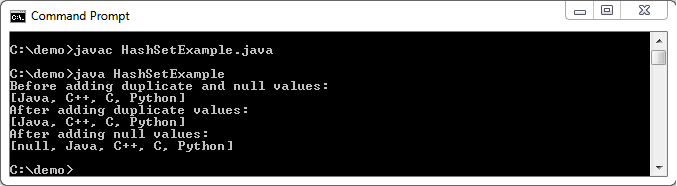
输出:
HashSet的示例
在下面的示例中,我们可以看到重复值未存储在HashSet中,并且空值只能存储一次。
import java.util.*;
public class HashSetExample
{
public static void main(String args[])
{
HashSet<String> hs= new HashSet<String>();
hs.add("Java");
hs.add("Python");
hs.add("C++");
hs.add("C");
System.out.println("Before adding duplicate and null values: ");
System.out.println(hs);
hs.add("Python");
hs.add("C");
System.out.println("After adding duplicate values: ");
System.out.println(hs);
hs.add(null);
hs.add(null);
System.out.println("After adding null values: ");
System.out.println(hs);
}
}
输出: