ETL 过程
ETL 过程
ETL 代表提取、转换和加载。 ETL 是一个用于提取数据、转换数据和将数据加载到最终源的过程。 ETL 遵循将数据从源系统加载到数据仓库的过程。
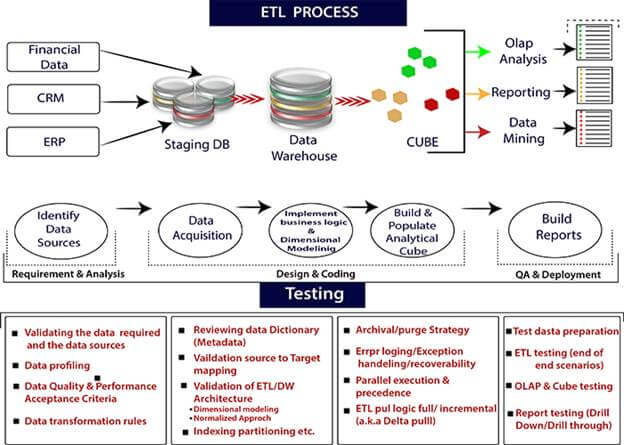
执行 ETL 过程的步骤是:
Extraction
Extraction 是第一个过程,从不同来源(如文本文件、XML 文件、Excel 文件、
转换
转换是 ETL 过程的第二步,其中所有收集的数据都已转换为相同的格式。根据我们的要求,格式可以是任何内容。在这一步中,将一组函数规则应用于提取的数据,将其转换为单一的标准格式。它可能涉及以下任务:
过滤: 只有特定属性加载到数据仓库中。
清理: 用特定的默认值填充空值。
加入: 将多个属性合并为一个。
拆分: 将单个属性拆分为多个属性。
排序: 根据属性对元组进行排序。
加载
加载是 ETL 过程的最后一步。大块数据从各种来源收集,转换,最后加载到数据仓库。
ETL是从不同来源系统提取数据,转换数据,加载数据的过程进入数据仓库。 ETL 过程需要包括开发人员、分析师、测试人员、高层管理人员在内的各种利益相关者的积极投入。
ETL(提取、转换和加载)是从原始数据中提取信息的自动化过程。分析并将其转换为可以满足业务需求的格式并将其加载到数据仓库中。 ETL 通常汇总数据以减少其大小并提高特定类型分析的性能。
ETL 过程使用流水线概念。在这个概念中,数据一提取出来,就可以进行转换,在转换的过程中,可以得到新的数据。并且当修改后的数据被加载到数据仓库时,已经提取的数据可以被转换。
在构建 ETL 基础架构时,我们必须整合数据源,仔细规划和测试以确保我们正确转换源数据。
此处,我们将解释构建 ETL 基础架构的三种方法,以及另一种不使用 ETL 构建数据管道的方法。
1) 使用批处理构建 ETL 管道
这里是构建传统 ETL 过程的过程,其中我们从源数据库到数据仓库。开发企业 ETL Pipeline 具有挑战性;我们通常会依赖 ETL 工具,例如 Stitch 和 Blendo,它们可以简化和自动化流程。
使用批处理构建 ETL,这里是 ETL 最佳实践。
1) 参考数据: 在这里,我们将创建一组数据来定义允许值的集合,并且可能包含数据。
示例: 在国家/地区数据字段中,我们可以定义允许的国家/地区代码。
2) 从数据参考中提取: ETL 步骤的成功在于正确提取数据。大多数ETL系统结合了来自多个源系统的数据,每个系统都有其数据组织和格式,包括关系数据库、非关系数据库、XML、JSON、CSV文件,成功提取后将数据转换为单一格式以标准化
3) 数据验证: 一个自动化过程确认从源中提取的数据是否具有预期值。例如,数据字段应包含过去一年金融交易数据库中过去 12 个月内的有效日期。如果数据未通过验证规则,验证引擎将拒绝该数据。我们会定期分析被拒绝的记录,以确定出了什么问题。在这里我们更正源数据或修改提取的数据以解决下一批中的问题。
4) 转换数据: 去除无关或错误的数据,应用业务规则,检查数据完整性(确保数据在源中没有损坏或被 ETL 损坏,并且在前几个阶段没有丢失数据),并根据需要创建聚合。如果我们分析收入,我们可以将发票的美元金额汇总为每日或每月的总额。我们需要编写和测试一系列可以实现所需转换的规则或函数,并在提取的数据上运行它们。
5) 阶段: 我们通常不会将转换后的数据直接加载到目标数据仓库中。应首先将数据输入临时数据库,以便在出现问题时更容易回滚。此时,我们还可以生成合规审计报告或诊断和修复数据问题。
6) 发布到数据仓库: 将数据加载到目标表。某些数据仓库每次都会覆盖现有信息,ETL 管道每天、每月或每周加载一个新批次。换句话说,ETL 可以在不覆盖的情况下添加新数据,时间戳表明它是唯一的。一定要慎重,防止数据仓库因磁盘空间和性能限制而"爆仓"。
2) 使用流处理构建 ETL 管道
现代数据处理通常包括实时数据。例如,来自大型电子商务网站的网络分析数据。在这些用例中,我们无法大批量提取和转换数据,需要对数据流执行 ETL,这意味着当客户端应用程序向数据源写入数据时,应立即对数据进行处理、转换并保存到目标数据存储。现在有许多流处理工具可用,包括 apache Samza、Apache store 和 Apache Kafka。
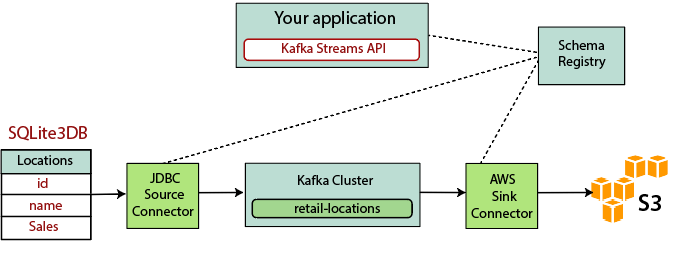
基于 Kafka 构建流式 ETL 涉及以下几点:
1) 将数据提取到 Kafka: JDBC 连接器拉取每一行源表。当客户端应用程序向表中添加行时,Kafka 会自动将它们作为新消息写入 Kafka 主题,从而启用实时数据流。
2) 从 Kafka 中拉取数据: ETL 应用程序从 Kafka 主题中提取消息作为 Avro 记录,它创建一个 Avro 模式文件并反序列化它们,并从消息中创建 KStream 对象。
3) 在KStream对象中转换数据: 使用Kafka Streams API,流处理器一次接收一条记录,对其进行处理,并可以从下游产生一条或多条输出记录处理器。这些可以一次转换一条消息,根据条件对其进行过滤,或对多条消息执行数据操作。
4) 将数据加载到其他系统: ETL 应用程序仍然持有数据,现在这需要将其流式传输到目标系统中,例如数据仓库或数据湖。它们的目的是使用 S3 接收器连接器将数据流式传输到 Amazon S3、我们可以实现与其他系统的集成。例如: 使用 Amazon Kinesis将数据流式传输到 Redshift 数据仓库。

