Pig COUNT
Apache Pig COUNT 函数
Apache Pig COUNT 函数用于计算包中元素的数量。它需要一个用于全局计数的前面的 GROUP ALL 语句和一个用于组计数的 GROUP BY 语句。它忽略空值。
COUNT 函数示例
在这个示例中,我们计算包中的元组。
执行 COUNT 函数的步骤
在本地机器上创建一个文本文件并插入元组列表。
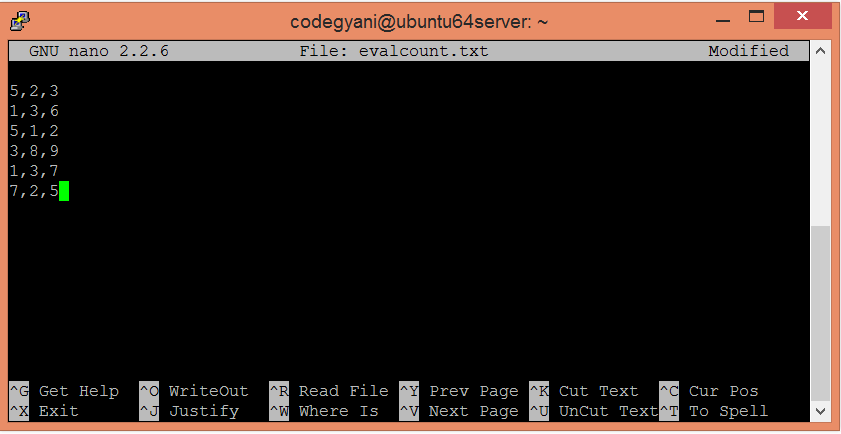 检查插入到文本文件中的元组。
检查插入到文本文件中的元组。
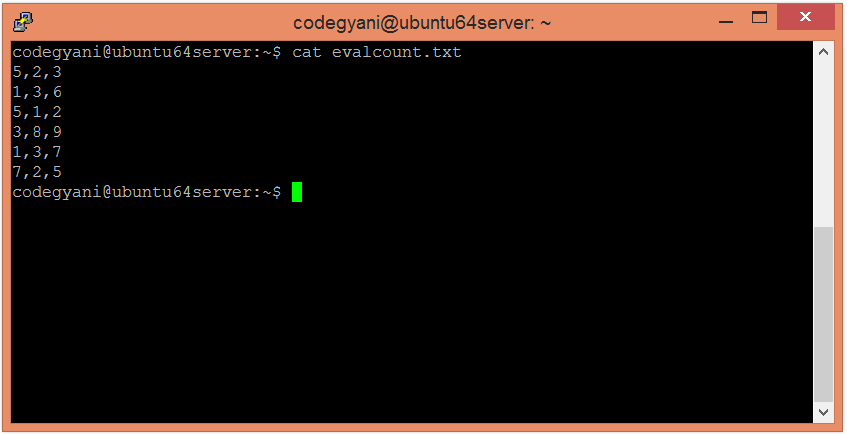 上传特定目录下 HDFS 上的文本文件。
上传特定目录下 HDFS 上的文本文件。
$ hdfs dfs-put evalcount.txt /pigexample
开启猪 MapReduce 运行模式。
加载包含数据的文件。
grunt> A = LOAD '/pigexample/evalcount.txt' USING PigStorage(',') AS (a1:int,a2:int,a3:int) ;
现在,执行并验证数据。
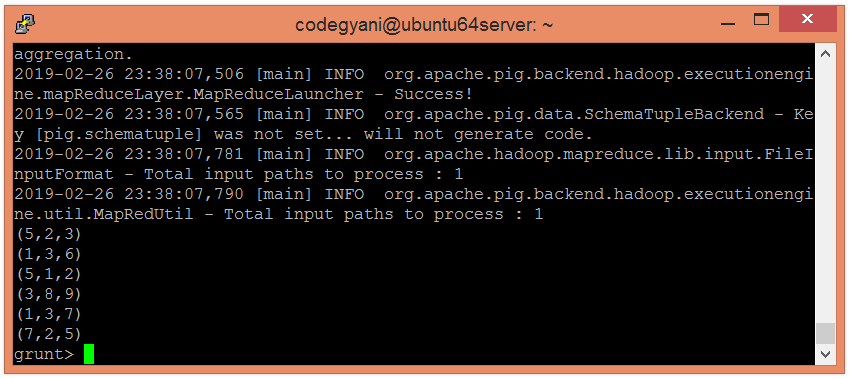 让我们根据"a1"字段对数据进行分组。
让我们根据"a1"字段对数据进行分组。
grunt> B = GROUP A BY a1;
grunt> DUMP B;
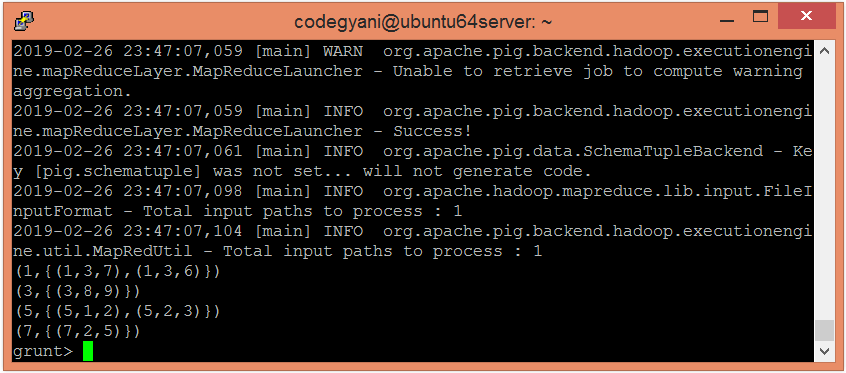 让我们返回给定元组的计数。
让我们返回给定元组的计数。
grunt> Result = FOREACH B GENERATE COUNT(A);
grunt> DUMP Result;
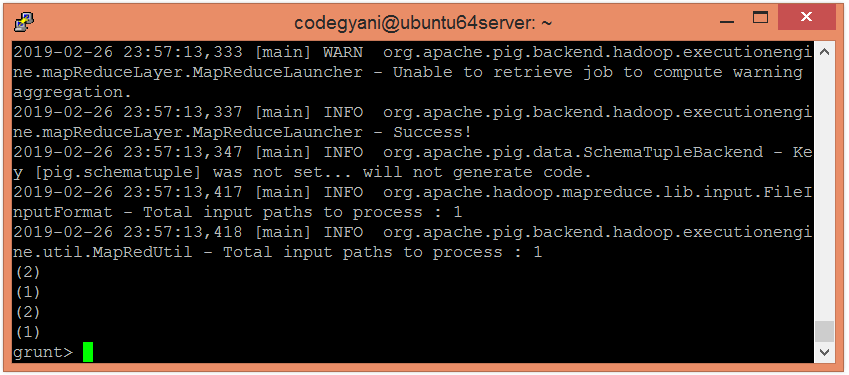
在这里,我们得到了想要的输出。

