人工智能无监督学习:聚类
人工智能无监督学习:聚类详细操作教程
无监督机器学习算法没有任何监督者提供任何指导。 这就是为什么它们与真正的人工智能紧密结合的原因。
在无人监督的学习中,没有正确的答案,也没有监督者指导。 算法需要发现用于学习的有趣数据模式。
什么是聚类?
基本上,它是一种无监督学习方法,也是用于许多领域的统计数据分析的常用技术。 聚类主要是将观测集合划分为子集(称为聚类)的任务,以同一聚类中的观测在一种意义上相似并且与其他聚类中的观测不相似的方式。 简而言之,可以说聚类的主要目标是根据相似性和不相似性对数据进行分组。
例如,下图显示了不同群集中的类似数据 -
数据聚类算法
以下是数据聚类的几种常用算法 -
K-Means算法K均值聚类算法是众所周知的数据聚类算法之一。 我们需要假设簇的数量已经是已知的。 这也被称为平面聚类。 它是一种迭代聚类算法。 该算法需要遵循以下步骤 -
第1步 - 需要指定所需的K个子组的数量。
第2步 - 修复群集数量并将每个数据点随机分配到群集。 换句话说,我们需要根据群集数量对数据进行分类。
在这一步中,计算聚类质心。
由于这是一种迭代算法,因此需要在每次迭代中更新K个质心的位置,直到找到全局最优值或换句话说质心到达其最佳位置。
以下代码将有助于在Python中实现K-means聚类算法。 我们将使用Scikit-learn模块。
导入必需的软件包 -
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
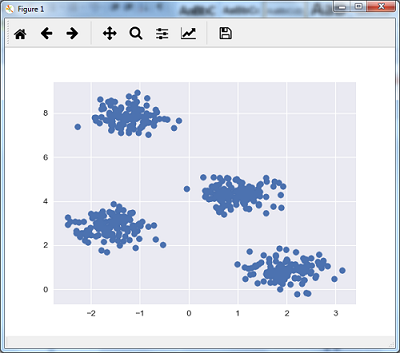
以下代码行将通过使用sklearn.dataset包中的make_blob来生成包含四个blob的二维数据集。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)
可以使用下面的代码可视化数据集 -
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
plt.scatter(X[:, 0], X[:, 1], s = 50);
plt.show()
得到以下结果 -
在这里,将kmeans初始化为KMeans算法,以及多少个群集(n_clusters)所需的参数。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
kmeans = KMeans(n_clusters = 4)
需要用输入数据训练K-means模型。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
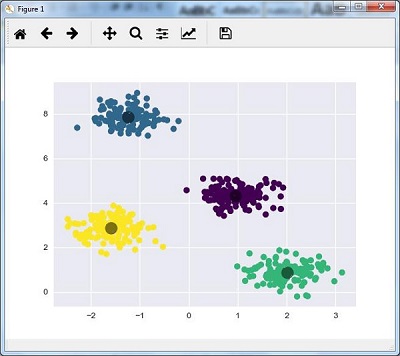
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis')
centers = kmeans.cluster_centers_
下面给出的代码将根据数据绘制和可视化机器的发现,并根据要找到的聚类数量进行拟合。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5);
plt.show()
得到以下结果 -
均值偏移算法
它是另一种在无监督学习中使用的流行和强大的聚类算法。 它不做任何假设,因此它是非参数算法。 它也被称为分层聚类或均值聚类分析。 以下将是该算法的基本步骤 -
首先,需要从分配给它们自己的集群的数据点开始。
现在,它计算质心并更新新质心的位置。
通过重复这个过程,向簇的顶点靠近,即朝向更高密度的区域移动。
该算法停止在质心不再移动的阶段。
在下面的代码的帮助下,在Python中实现了Mean Shift聚类算法。使用Scikit-learn模块。
导入必要的软件包 -
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
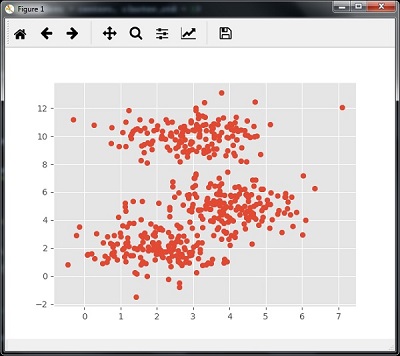
以下代码将通过使用sklearn.dataset包中的make_blob来生成包含四个blob的二维数据集。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
from sklearn.datasets.samples_generator import make_blobs
可以用下面的代码可视化数据集 -
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
centers = [[2,2],[4,5],[3,10]]
X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1)
plt.scatter(X[:,0],X[:,1])
plt.show()
执行上面示例代码,得到以下结果 -
现在,我们需要用输入数据来训练Mean Shift聚类模型。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
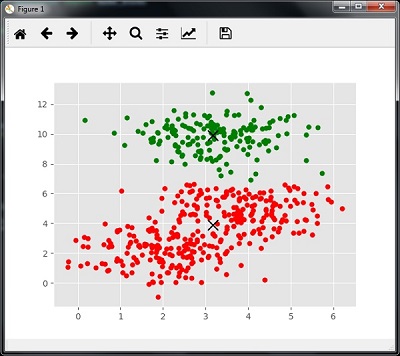
以下代码将按照输入数据打印聚类中心和预期的聚类数量 -
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2
下面给出的代码将有助于根据数据绘制和可视化机器的发现,并根据要找到的聚类数量进行装配。
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10)
plt.show()
执行上面示例代码,得到以下结果 -
测量群集性能
现实世界的数据不是自然地组织成许多独特的群集。 由于这个原因,要想象和推断推理并不容易。 这就是为什么需要测量聚类性能及其质量。 它可以在轮廓分析的帮助下完成。
轮廓分析
该方法可用于通过测量群集之间的距离来检查聚类的质量。 基本上,它提供了一种通过给出轮廓分数来评估像集群数量这样的参数的方法。 此分数是衡量一个群集中每个点与相邻群集中的点的距离的度量。
分析轮廓分数得分范围为[-1,1]。 以下是对这个分数的分析 -
得分为+1分 - 得分接近+1表示样本距离相邻集群很远。
得分为0分 - 得分0表示样本与两个相邻群集之间的决策边界处于或非常接近。
得分为-1分 - 得分为负分数表示样本已分配到错误的群集。
计算轮廓分数
在本节中,我们将学习如何计算轮廓分数。
轮廓分数可以通过使用以下公式来计算 -