混淆矩阵
混淆矩阵详细操作教程
这是衡量分类问题性能的最简单方法,其中输出可以是两种或多种类型的类。混淆矩阵不过是具有二维的表。 "实际"和"预测",而且两个维度都具有"真阳性(TP)","真阴性(TN)","假阳性(FP)","假阴性(FN)",如下所示-
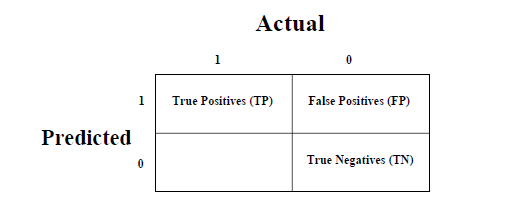
与混淆矩阵相关的术语的解释如下-
正值(TP)-数据点的实际类别和预测类别都为1的情况。
真负数(TN)-数据点的实际类别和预测类别都为0的情况。
假阳性(FP)-数据点的实际类别为0而数据点的预测类别为1的情况。
假阴性(FN)-数据点的实际类别为1,数据点的预测类别为0的情况。
我们可以借助sklearn的
confusion_matrix()函数找到混淆矩阵。借助以下脚本,我们可以找到上面构建的二进制分类器的混淆矩阵-
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-27
from sklearn.metrics import confusion_matrix
输出
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-27
[[ 73 7]
[ 4 144]]
准确性
它可以定义为我们的ML模型做出的正确预测的数量。我们可以借助下面的公式通过混淆矩阵轻松地计算它-
$$ Accuracy = \ frac {TP + TN} {TP + FP + FN + TN} $$
对于上述内置的二进制分类器,TP + TN = 73 + 144 = 217和TP + FP + FN + TN = 73 + 7 + 4 + 144 = 228。
因此,准确度= 217/228 = 0.951754385965,与创建二进制分类器后计算出的结果相同。
精度
用于文档检索的精度可以定义为我们的ML模型返回的正确文档数。我们可以借助下面的公式通过混淆矩阵轻松地计算它-
$$ Precision = \ frac {TP} {TP + FP} $$
对于上面构建的二进制分类器,TP = 73,TP + FP = 73 + 7 = 80。
因此,精度= 73/80 = 0.915
召回率或灵敏度
召回率可以定义为我们的ML模型返回的肯定数。我们可以借助下面的公式通过混淆矩阵轻松地计算它-
$$ Recall = \ frac {TP} {TP + FN} $$
对于上面构建的二进制分类器,TP = 73,TP + FN = 73 + 4 = 77。
因此,精度= 73/77 = 0.94805
专长
与召回相反,
特异性可以定义为我们的ML模型返回的负数。我们可以借助下面的公式通过混淆矩阵轻松地计算它-
$$ Specificity = \ frac {TN} {TN + FP} $$
对于上面构建的二进制分类器,TN = 144和TN + FP = 144 + 7 = 151。
因此,精度= 144/151 = 0.95364

