Solr 文本分析
Solr文本分析
Apache Solr 文本分析可用于消除术语之间的表面差异以解决更复杂的问题,从而提供良好的用户体验,例如特定语言的解析、词形还原, 和词性标记。我们将在前面更详细地讨论所有这些术语。 Apache Solr 具有用于执行基本文本分析的广泛框架,例如-删除称为停用词的常用词并执行额外的复杂分析。综上所述,Solr 的文本分析框架具有如此强大的功能和灵活性,对于新用户来说似乎过于复杂和令人生畏。可以说,Solr 使复杂的文本分析变得如此简单,但这样做会使简单的任务变得有点难以管理。这就是为什么 Solr 在其示例"schema.xml"中内置了如此多的预配置字段类型以确保新用户在开箱即用的情况下使用 Solr 时有一个很好的地方开始文本分析的原因。学习完本教程后,您将能够处理这种强大的结构来分析我们将要面对的大部分内容。
我们演示了文本分析方法并为我们的文件构建分析解决方案。为此,我们将解决一个复杂的文本分析问题,以获得成功所需的策略和机制。具体来说,我们将了解使用 Solr 进行文本分析的给定基本元素:
Solr 的基本文本分析元素,包括分析器、标记器和标记过滤器链。
用于在索引、查询处理和在 schema.xml 中定义自定义字段类型期间分析文本。
标准文本分析技术,例如小写、删除停用词、词干提取、同义词扩展和删除重音。
具体来说,我们将了解如何分析来自 Twitter 等网站的微博内容。推文提出了独特的挑战,需要我们仔细考虑有多少用户会使用我们的搜索结果。具体来说,我们将看到如何:
在保留 #hashtags 和 @mentions 方面将重复的字符折叠到最多两个
使用自定义令牌过滤器来解析缩短的 bit.ly 样式的 URL
分析微博文本
让我们继续我们在本页介绍的示例微博搜索应用程序。在这里,我们将设计和实现从不同社交媒体网站(如 Twitter、Facebook 等)搜索微博的解决方案。由于本教程的基本重点是文本分析,让我们仔细看看示例微博文档中的文本字段。
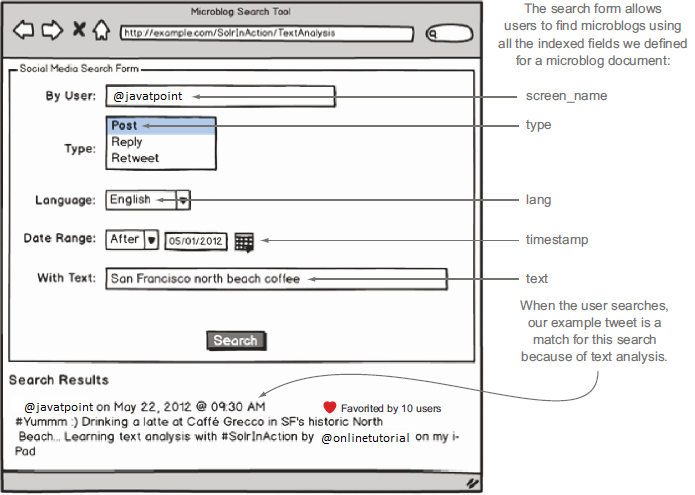
这里是我们要分析的文本:
#Yummm :) Drinking a latte at Caffé Grecco in SF's historic North Beach... Learning text analysis with #SolrInAction by @onlinetutorial on my iPad
正如我们在介绍中所讨论的,文本分析的主要目标是让您的用户可以使用自然语言进行搜索,而不必担心他们搜索词的所有可能形式。在上图中,用户通过文本字段搜索旧金山北滩咖啡,这是考虑到北滩所有一流咖啡馆的自然查询;也许我们的用户正试图通过搜索社交媒体内容在北海滩找到一个喝咖啡的好地方。
我们声明我们的示例推文应该与此查询完全匹配,即使精确文本与北匹配海滩、旧金山和咖啡不会出现在我们的示例推文中。是的,北滩在我们的文件中,但在搜索中大小写很重要,除非您采取特定措施使搜索索引不区分大小写。由于用户搜索查询中使用的术语与表中显示的文档中的术语之间存在关系,因此我们断言我们的示例文档应该与此查询高度匹配。
| 用户搜索文本 |
文档中的文本 |
| San Francisco |
SF |
| north beach |
North Beach |
| Coffee |
latte, Caffé |
基本文本分析
正如我们之前了解到的,schema.xml 中的 <types> 部分为文档中所有可能的字段定义了 <fieldType> 元素,在每个 <fieldType>定义了用于查询和索引分析的字段的格式和工作方式。示例模式提供了适用于 Solr 大量搜索应用程序的字段类型的广泛列表。如果任何预定义的 Solr 字段类型不能满足我们的需求,我们可以在 Solr 插件框架的帮助下构建我们自己的字段类型。
假设包含的所有字段都组织了时间戳和语言代码等数据.在这种情况下,我们可能不需要使用 Solr,因为关系数据库在搜索和索引结构化数据方面是系统的。操作非结构化文本是 Solr 真正展示其能力的地方。因此,示例 Solr 模式预定义了一些用于分析文本的强大字段类型。它为 text_general(一种较简单的字段类型)提供 XML 定义,作为分析推文文本的起点。本教程中的示例依赖于对 Solr 示例附带的 schema.xml 的一些小的自定义。我们建议将 Solr 示例附带的 schema.xml 文件替换为 $SOLR_IN_ACTION/example-docs/ch6/schema.xml 中的自定义版本。具体来说,您需要通过执行以下操作来覆盖 $SOLR_INSTALL/example/solr/collection1/conf/schema.xml:
cp $SOLR_IN_ACTION/example-docs/ch6/schema.xml
➥ $SOLR_INSTALL/example/solr/collection1/conf/
另外,需要将wdfftypes.txt文件复制到conf目录下:
cp $SOLR_IN_ACTION/example-docs/ch6/wdfftypes.txt
➥ $SOLR_INSTALL/example/solr/collection1/conf/
最后,从一个干净的石板开始(因为我们已经在前面的章节中索引了一些测试文档),您应该删除数据目录中的所有内容以开始一个空的搜索索引:
rm-rf $SOLR_INSTALL/example/solr/collection1/data/*
复制自定义 schema.xml 和 wdfftypes.txt 后,您需要从 Solr 管理控制台的核心管理页面重新加载 collection1 核心或重新启动 Solr。
Analyzer
在<fieldType> 元素中,您应该至少定义一个,它将决定如何分析文本。在实践中通常定义两个单独的 元素: 一个用于分析文本,另一个用于索引,由用户在执行搜索操作时输入。 "text_general"字段使用这种方法进行此操作。
暂时想一想为什么我们可能会使用不同的分析器进行索引和查询。如果您经常有额外的分析来处理超出文档索引所需的查询,这将有所帮助。例如: 如果通常在查询文本分析期间添加同义词,以避免只会增加索引的大小并更容易控制同义词。
但是,我们可以定义两个不同的分析器。应用于查询词的分析必须与索引期间文本的分析方式兼容。考虑到分析器在建立索引时词条配置过小的情况,不会降低查询词条。 Solr 用户搜索 North Beach 将找不到我们的示例推文,因为索引包含"north"和"beach"的小字母形式。
Tokenizer
在 Solr 中,每个 将文本分析过程分为两个阶段:
标记化(解析)
令牌过滤
还有第三个阶段允许在标记化时进行预处理,您可以在其中应用字符过滤器。在标记化阶段,文本将通过解析拆分为标记流。最基本的标记器是一个 WhitespaceTokenizer,它只能用于在空白处拆分文本。另一个是 StandardTokenizer,它执行智能解析以拆分空格、标点符号并正确处理 URL、首字母缩略词和电子邮件地址。我们需要为我们的tokenizer指定工厂的Java实现类来定义tokenizer。要使用通用的 Standard-Tokenizer,您需要指定 solr.StandardTokenizerFactory。 <tokenizer class="solr.StandardTokenizerFactory" />
在 Solr 中,我们可以指定工厂类而不是底层的 Tokenizer 类(实现),因为许多标记器不提供默认的无参数构造函数。如果我们使用工厂方法,Solr 为我们提供了一种在 XML 中定义任何标记器的标准方法。所有工厂类都知道如何转换 XML 配置属性以创建特定 Tokenizer 实现类的实例。所有这些都会产生一个令牌流,可以由零个或多个过滤器处理以转换令牌。

