SQLServer GROUP BY
SQL Server GROUP BY子句用于收集多个记录中的数据并将结果按一个或多个列分组。它与SELECT语句一起使用。
语法:
SELECT expression1, expression2, ... expression_n,
aggregate_function (expression)
FROM tables
[WHERE conditions]
GROUP BY expression1, expression2, ... expression_n;
参数说明
expression1,expression2,... expression_n: 这些表达式未封装在聚合函数中,必须包含在GROUP中BY子句。
aggregate_function: 它可以是诸如SUM,COUNT,MIN,MAX或AVG函数之类的函数。
表: 您要从中检索记录的表。在FROM子句中必须至少列出一个表。
在什么情况下: 这是可选的。选择记录必须满足的条件。
示例:
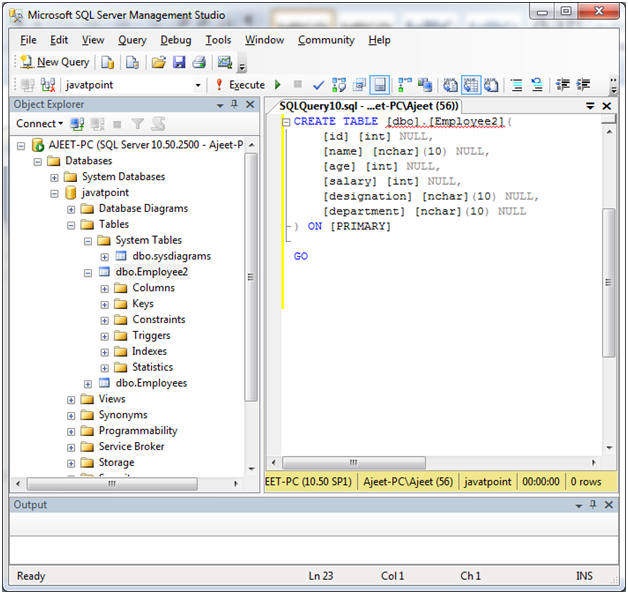
首先创建一个表" Employee2":
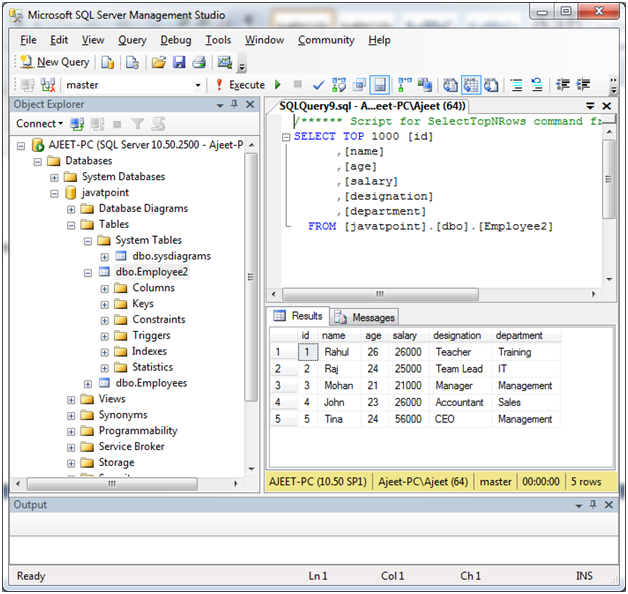
以下是表中某些插入数据的列表。
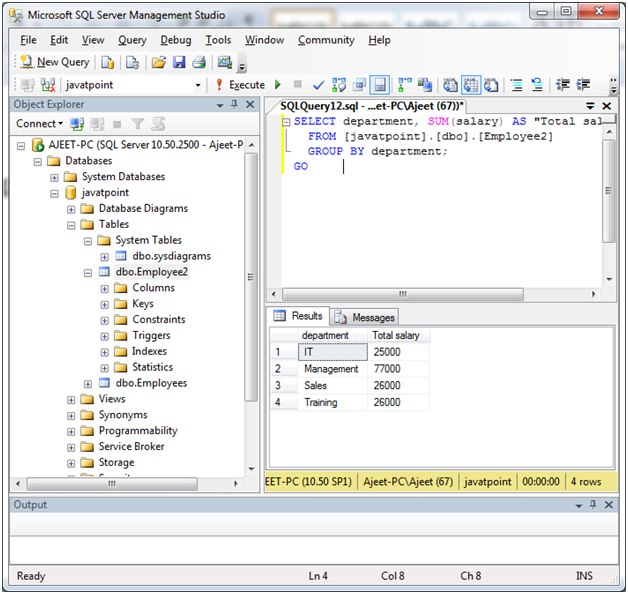
使用SUM函数组
请参见以下示例,其中我们使用SUM函数从" Employee2"分组GROUP BY部门:
SELECT department, SUM(salary) AS "Total salary"
FROM [lidihuo].[dbo].[Employee2]
GROUP BY department;
输出:
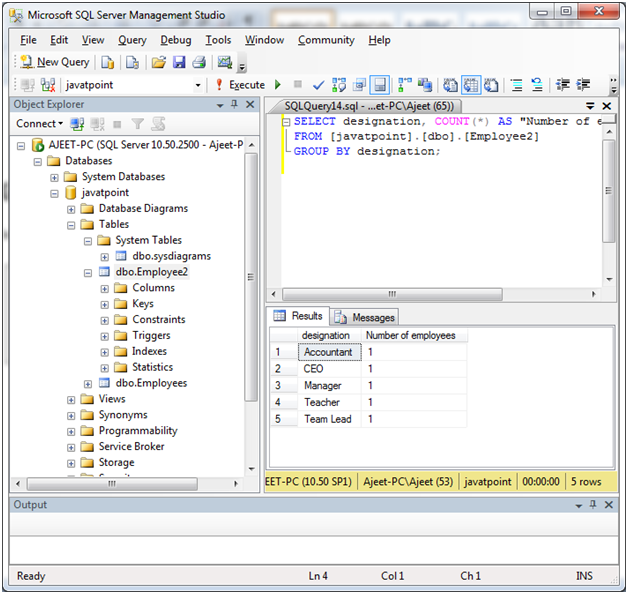
通过使用COUNT函数组
请参见以下示例,其中我们使用COUNT函数从" Employee2"中指定GROUP BY:
SELECT designation, COUNT(*) AS "Number of employees"
FROM [lidihuo].[dbo].[Employee2]
GROUP BY designation;
输出:
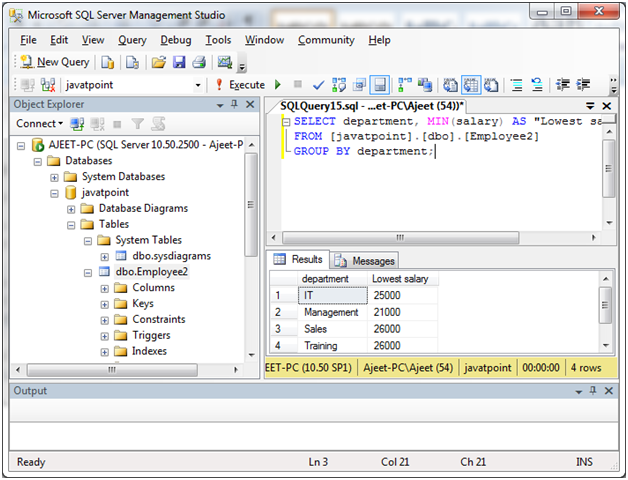
通过使用MIN函数的组
请参见本示例,其中我们根据部门使用MIN函数根据" Employee2"的薪水分组部门。
这将根据部门获取最低工资:
SELECT department, MIN(salary) AS "Lowest salary"
FROM [lidihuo].[dbo].[Employee2]
GROUP BY department;
输出:
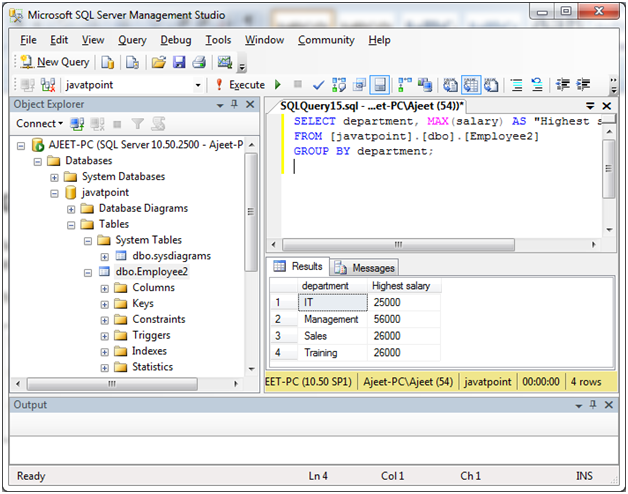
通过使用MAX函数组
请参见本示例,其中我们根据" Employee2"使用MAX函数的薪水来按部门分组。
这将根据部门获取最高薪水:
SELECT department, MAX(salary) AS "Highest salary"
FROM [lidihuo].[dbo].[Employee2]
GROUP BY department;
输出: