Tajo SQL语句
Tajo SQL语句
在上一章中,您已经了解了如何在 Tajo 中创建表。本章介绍 Tajo 中的 SQL 语句。
创建表语句
在移动创建表之前,在 Tajo 安装目录路径中创建一个文本文件"students.csv"如下-
students.csv
| Name |
Address |
Age |
Marks |
| Adam |
23 New Street |
21 |
90 |
| Amit |
12 Old Street |
13 |
95 |
| Bob |
10 Cross Street |
12 |
80 |
| David |
15 Express Avenue |
12 |
85 |
| Esha |
20 Garden Street |
13 |
50 |
| Ganga |
25 North Street |
12 |
55 |
| Jack |
2 Park Street |
12 |
60 |
| Leena |
24 South Street |
12 |
70 |
| Mary |
5 West Street |
12 |
75 |
| Peter |
16 Park Avenue |
12 |
95 |
文件创建完成后,移至终端并一一启动Tajo服务器和shell。
创建数据库
使用以下命令创建一个新数据库-
查询
default> create database sampledb;
OK
连接到现在创建的数据库"sampledb"。
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.
然后,在"sampledb"中创建一个表如下-
查询
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;
结果
以上查询将生成以下结果。
到这里,外部表就创建好了。现在,您只需输入文件位置。如果您必须从 hdfs 分配表,请使用 hdfs 而不是文件。
接下来,
"students.csv" 文件包含逗号分隔值。
text.delimiter 字段用‘,’分配。
您现在已经在"sampledb"中成功创建了"mytable"。
显示表格
要在 Tajo 中显示表格,请使用以下查询。
查询
sampledb> \d
mytable
sampledb> \d mytable
结果
以上查询将生成以下结果。
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
列表表
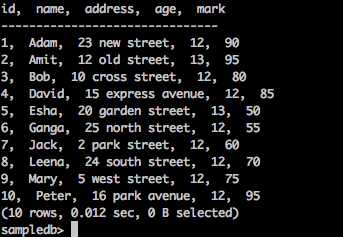
要获取表中的所有记录,请键入以下查询-
查询
sampledb> select * from mytable;
结果
以上查询将生成以下结果。
插入表语句
Tajo 使用以下语法在表中插入记录。
语法
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;
Tajo 的插入语句类似于 SQL 的
INSERT INTO SELECT 语句。
查询
让我们创建一个表来覆盖现有表的表数据。
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \d
结果
以上查询将生成以下结果。
插入记录
要在"test"表中插入记录,请键入以下查询。
查询
sampledb> insert overwrite into test select * from mytable;
结果
以上查询将生成以下结果。
Progress: 100%, response time: 0.518 sec
此处,"mytable"记录覆盖了"test"表。如果您不想创建"test"表,请立即分配物理路径位置,如插入查询的替代选项中所述。
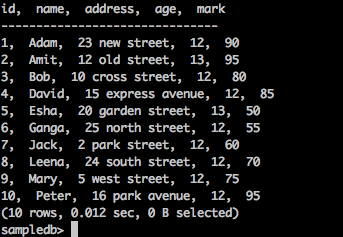
获取记录
使用以下查询列出"test"表中的所有记录-
查询
sampledb> select * from test;
结果
以上查询将生成以下结果。
此语句用于添加、删除或修改现有表的列。
要重命名表,请使用以下语法-
Alter table table1 RENAME TO table2;
查询
sampledb> alter table test rename to students;
结果
以上查询将生成以下结果。
要检查更改的表名,请使用以下查询。
sampledb> \d
mytable
students
现在表"test"更改为"students"表。
添加列
要在"students"表中插入新列,请键入以下语法-
Alter table <table_name> ADD COLUMN <column_name> <data_type>
查询
sampledb> alter table students add column grade text;
结果
以上查询将生成以下结果。
设置属性
此属性用于更改表格的属性。
查询
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OK
这里分配了压缩类型和编解码器属性。
要更改文本分隔符属性,请使用以下内容-
查询
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OK
结果
以上查询将生成以下结果。
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXT
以上结果表明使用"SET"属性更改了表的属性。
SELECT语句
SELECT 语句用于从数据库中选择数据。
Select 语句的语法如下-
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]
Where 子句
Where 子句用于从表中过滤记录。
查询
sampledb> select * from mytable where id > 5;
结果
以上查询将生成以下结果。
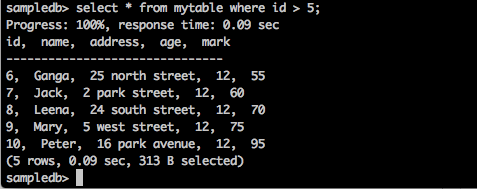
查询返回id大于5的学生的记录。
查询
sampledb> select * from mytable where name = ‘Peter’;
结果
以上查询将生成以下结果。
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12
结果仅过滤 Peter 的记录。
DISTINCT
表列可能包含重复值。 DISTINCT 关键字可用于仅返回不同(不同)的值。
语法
SELECT DISTINCT column1,column2 FROM table_name;
查询
sampledb> select distinct age from mytable;
结果
以上查询将生成以下结果。
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12
查询返回
mytable 中学生的不同年龄。
按条件分组
GROUP BY 子句与 SELECT 语句配合使用,将相同的数据分组。
语法
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;
查询
select age,sum(mark) as sumofmarks from mytable group by age;
结果
以上查询将生成以下结果。
age, sumofmarks
-------------------------------
13, 145
12, 610
此处,"mytable"列有两种类型的年龄 — 12 和 13、现在查询按年龄对记录进行分组,并生成相应学生年龄的总分。
有条款
HAVING 子句使您能够指定条件来过滤哪些组结果出现在最终结果中。 WHERE 子句在选定的列上放置条件,而 HAVING 子句在 GROUP BY 子句创建的组上放置条件。
语法
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]
查询
sampledb> select age from mytable group by age having sum(mark) > 200;
结果
以上查询将生成以下结果。
age
-------------------------------
12
查询按年龄对记录进行分组,当条件结果 sum(mark) > 200 时返回年龄。
按条件排序
ORDER BY 子句用于根据一列或多列按升序或降序对数据进行排序。 Tajo 数据库默认按升序对查询结果进行排序。
语法
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
查询
sampledb> select * from mytable where mark > 60 order by name desc;
结果
以上查询将生成以下结果。
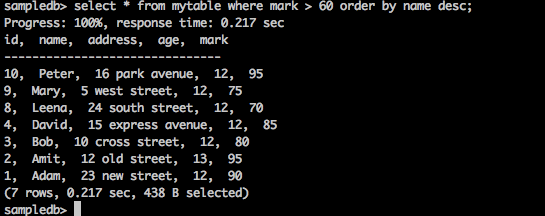
查询以降序返回分数大于60的学生姓名。
创建索引语句
CREATE INDEX 语句用于在表中创建索引。索引用于快速检索数据。当前版本仅支持存储在 HDFS 上的纯文本格式的索引。
语法
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }
查询
create index student_index on mytable(id);
结果
以上查询将生成以下结果。
要查看为列分配的索引,请键入以下查询。
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC nullS LAST )
这里,Tajo 中默认使用 TWO_LEVEL_BIN_TREE 方法。
删除表声明
Drop Table 语句用于从数据库中删除表。
语法
查询
sampledb> drop table mytable;
要检查表是否已从表中删除,请键入以下查询。
结果
以上查询将生成以下结果。
ERROR: relation 'mytable' does not exist
您还可以使用"\d"命令检查查询以列出可用的 Tajo 表。

