Linux grep正则
Linux grep正则表达式
grep工具具有以下使用正则表达式的选项:
-E: 将字符串读取为ERE(扩展正则表达式)
-G: 将字符串读取为BRE(基本正则表达式)
-P: 将字符串读取为PRCE(Perl正则表达式)
-F: 从字面上读取字符串。
打印与模式匹配的行
grep命令将搜索与指定模式匹配的行。
语法:
grep <pattern> <fileName>
示例:
grep t msg.txt
grep l msg.txt
grep v msg.txt
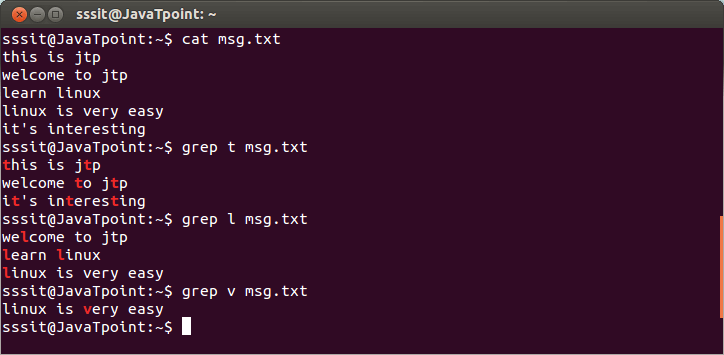
看上面的快照,显示所有匹配的模式行和模式突出显示。
串联字符
如果模式是串联字符,则必须按原样进行匹配,才能显示该行。
示例:
grep tp msg.txt
grep in msg.txt
grep is msg.txt
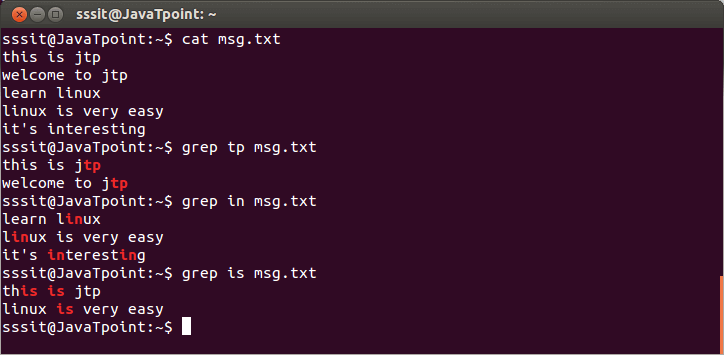
看上面的快照,显示与指定模式完全匹配的行。
一个或另一个
此处将管道(|)符号用作OR来表示一个或另一个。显示了所有三个版本。选项-E和-P语法相同,但-G语法使用(\)。
语法:
grep <option> <'pattern|pattern> <fileName>
示例:
grep-E 'j|g' msg.txt
grep-P 'j|g' msg.txt
grep-G 'j\|g' msg.txt
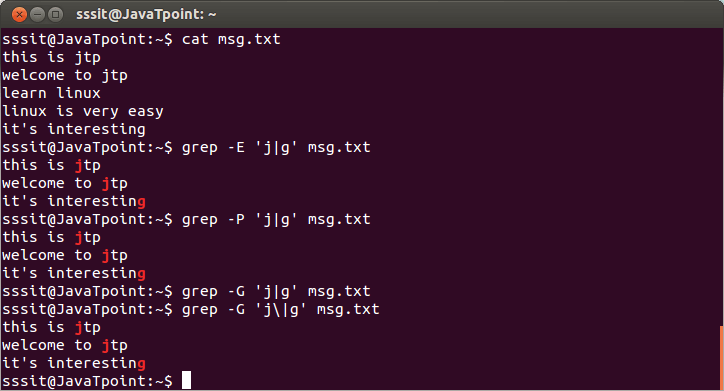
请看上面的快照,模式为'j'或'g'应该匹配以显示线条。
一个或多个/零个或多个
*表示某个模式出现零次或多次,而+表示一次出现多次。
语法:
grep <option> <'pattern*'> <fileName>
示例:
grep-E '1*' list
grep-E '1+' list
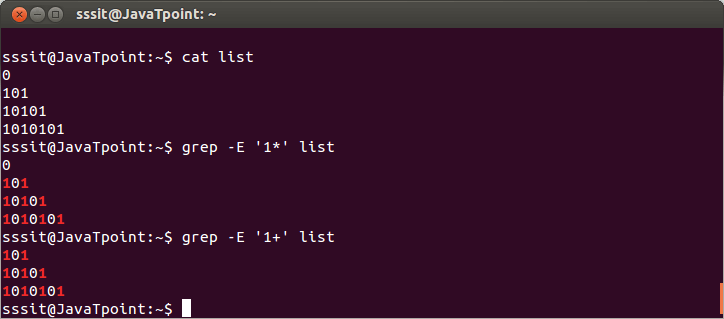
请看上面的快照,*字符显示零次或多次出现模式" 1" 。但是+字符会显示一次或多次。
匹配字符串的结尾
要匹配字符串的结尾,我们使用$符号。
语法:
grep <pattern>$ <fileName>
示例:
grep r$ dupli.txt
grep e$ dupli.txt
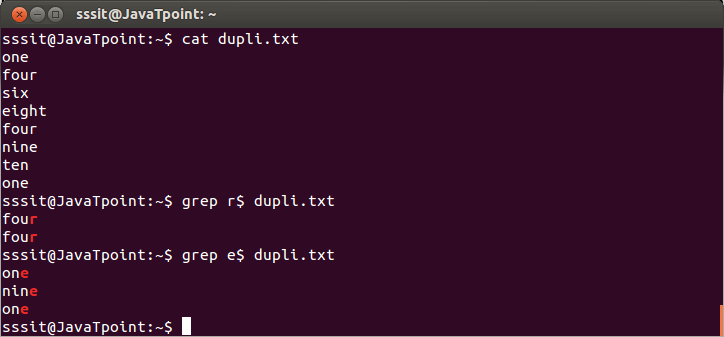
看上面的快照,显示与字符串结尾匹配的行
匹配字符串的开头
要匹配文件的开头或开头,我们使用脱字符号(^)。
语法:
grep ^<pattern> <fileName>
示例:
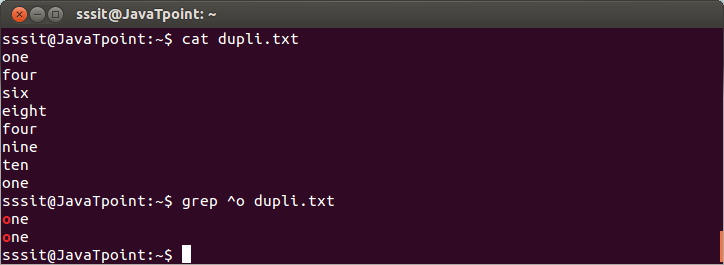
看上面的快照,显示的行与以下内容的开头或开头匹配一个字符串。
分隔单词
语法:
grep '\b<pattern>\b' <fileName>
示例:
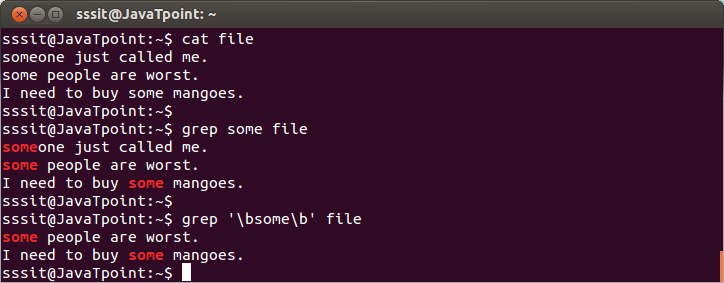
通过给命令" grep一些命令来查看上面的快照文件会显示所有与" some"一词匹配的行,但是通过给出命令" grep'\ bsome \ b'file" ,只会显示与单个单词" some"匹配的行。
注意: 这也可以在-w选项的帮助下完成。
语法:
grep-w <pattern> <fileName>
示例:
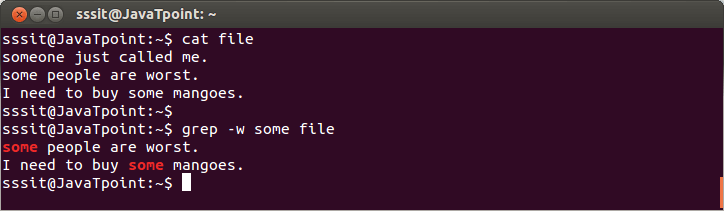
请看上面的快照,命令" grep-w some文件" 显示与 \ b 字符相同的结果。

