Linux uniq命令
Linux uniq命令
Linux uniq命令用于从文件中删除所有重复的行。而且,它可以用于显示任何单词的计数,仅重复行,忽略字符以及比较特定字段。它是 Linux 系统中最常用的命令之一。它经常与 sort命令一起使用,因为它会比较相邻的字符。它将丢弃所有相同的行并写入输出。
语法:
uniq [OPTION]... [INPUT [OUTPUT]]
选项:
uniq命令的一些有用的命令行选项如下:
-c,--count:它以出现次数为前缀。
-d,--repeated: 它用于打印重复的行,每组一个。
-D: 用于打印所有重复的行。
--all-repeated [= METHOD]:它与'-D'选项非常相似,这两个选项之间的区别在于,它允许用空行分隔组。
-f,--skip-fields = N:用于避免对前N个字段进行比较。
-group [= METHOD]:用于显示所有项目,并用空白分隔组
-i,-ignore-case用于在比较时忽略差异。
-s,-skip-chars = N: 用于避免比较前N个字符。
-u,--unique: 用于打印唯一行。
-z, --zero-terminated: 用于行定界符为NUL而不是换行符
-w,--check-chars=N: 它用于比较行中不超过N个字符。
--help: 用于显示帮助文档。
--version: 用于显示版本信息。
删除重复的行
要从文件中删除重复的行,请执行基本的uniq命令,如下所示:
上面的命令将从文件'dupli.txt'中删除重复的行。考虑以下输出:
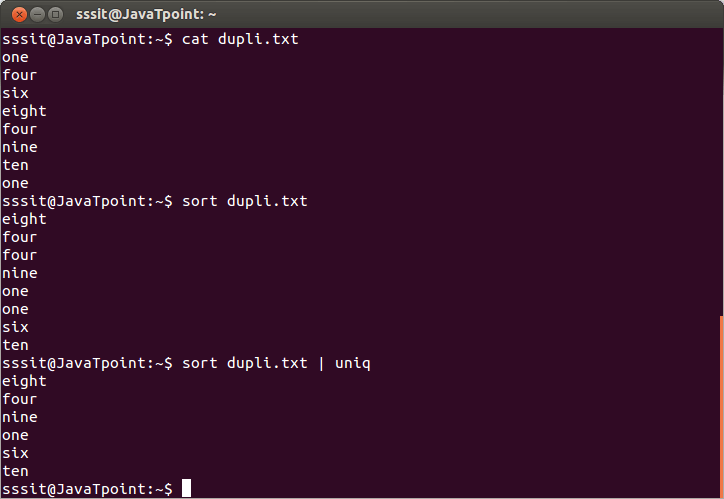
从上面的输出中,忽略重复的单词
计算一个单词的出现次数
我们可以使用uniq命令来计算一个单词的出现次数。 '-c'选项用于对单词进行计数。如下执行:
上面的命令将计算'dupli.txt'中的单词。考虑以下输出:
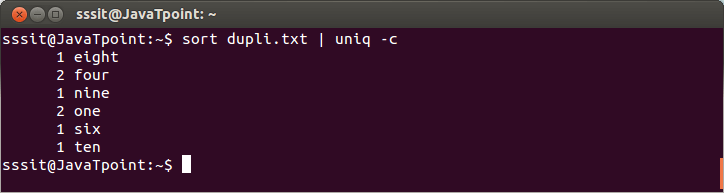
从上面的输出中,命令" sort dupli .txt | uniq-c"计算单词重复的次数。
显示重复的行
'-d'选项用于仅显示重复的行。它将仅显示文件中不止一次的行,并将输出写入标准输出。考虑以下命令:
上面的命令将仅显示重复的行。考虑以下输出:

显示唯一行
'-u'选项用于仅显示唯一行(不会重复)。它只会显示仅出现一次的行,并将结果写入标准输出。考虑以下命令:
上面的命令将仅显示文件'dupli.txt'中的唯一行。考虑以下输出:

忽略比较中的字符
"-s"选项用于忽略比较中的字符。它将忽略指定的字符数,并将结果显示到标准输出。考虑以下命令:
sort dupli.txt | uniq-s 2
以上命令将忽略文件'dupli.txt'中的前两个字符。考虑以下输出:

忽略比较中的字段
"-f"选项用于忽略这些字段。考虑以下命令:
上面的命令不会比较文件" dupli2.txt"中的前两个字段。考虑以下输出:

从上面的输出中,前两个字段是跳过,然后从文件" dupli2.txt"中比较其余所有字段。

