Weka 聚类
聚类算法在整个数据集中查找相似实例的组。 WEKA 支持多种聚类算法,如 EM、FilteredClusterer、HierarchicalClusterer、SimpleKMeans 等。您应该完全理解这些算法以充分利用 WEKA 功能。
与分类一样,WEKA 允许您以图形方式可视化检测到的集群。为了演示聚类,我们将使用提供的 iris 数据库。数据集包含三个类,每个类 50 个实例。每个类指一种鸢尾植物。
加载数据
在 WEKA 资源管理器中,选择
预处理 选项卡。单击
打开文件 ... 选项并在文件选择对话框中选择
iris.arff 文件。加载数据时,屏幕如下所示-
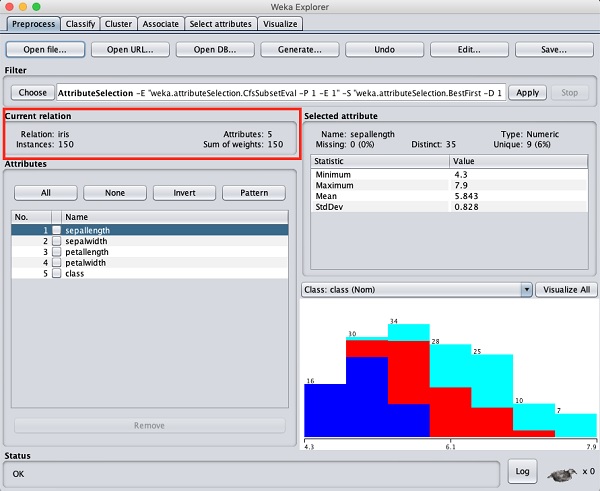
您可以观察到有 150 个实例和 5 个属性。属性名称被列为
sepallength、
sepalwidth、
petallength、
petalwidth 和
class.前四个属性是数字类型,而类是具有 3 个不同值的名义类型。检查每个属性以了解数据库的功能。我们不会对这些数据进行任何预处理,直接进行模型构建。
聚类
单击
Cluster 选项卡,将聚类算法应用于我们加载的数据。点击
选择按钮。您将看到以下屏幕-
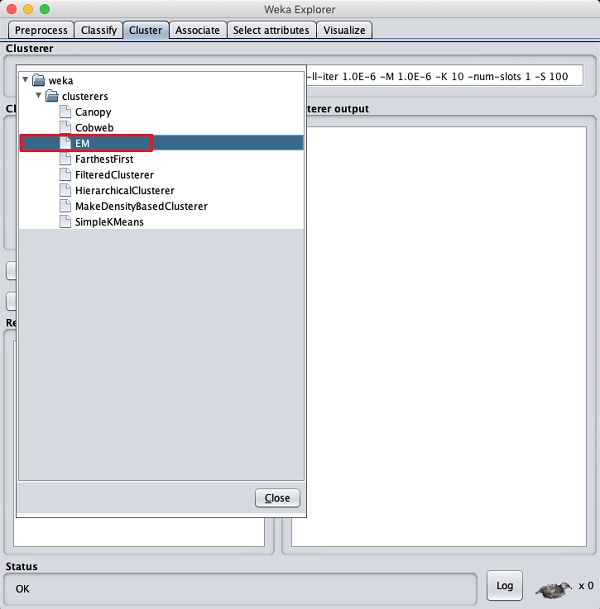
现在,选择
EM 作为聚类算法。在
Cluster mode 子窗口中,选择
Classes to Cluster Evaluation 选项,如下面的屏幕截图所示-
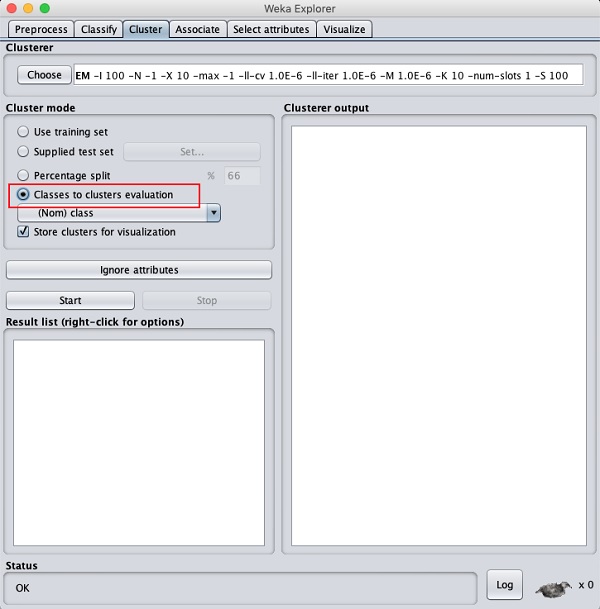
点击
开始按钮来处理数据。一段时间后,结果将显示在屏幕上。
接下来,让我们研究一下结果。
检查输出
数据处理的输出显示在下面的屏幕中-

从输出屏幕,您可以观察到-
在数据库中检测到 5 个集群实例。
Cluster 0 代表 setosa,Cluster 1 代表 virginica,簇 2 代表杂色,而最后两个簇没有任何与之关联的类。
如果向上滚动输出窗口,您还会看到一些统计数据,这些统计数据给出了各种检测到的集群中每个属性的均值和标准差。这显示在下面给出的屏幕截图中-
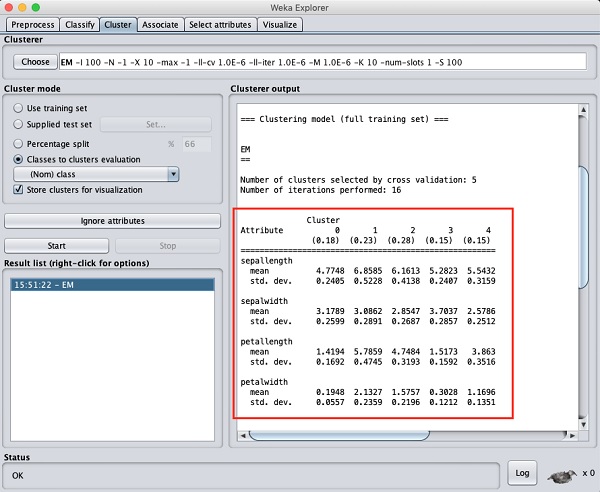
接下来,我们将看看集群的视觉表示。
可视化集群
要可视化集群,请右键单击
结果列表中的
EM结果。您将看到以下选项-
选择
可视化集群分配。您将看到以下输出-
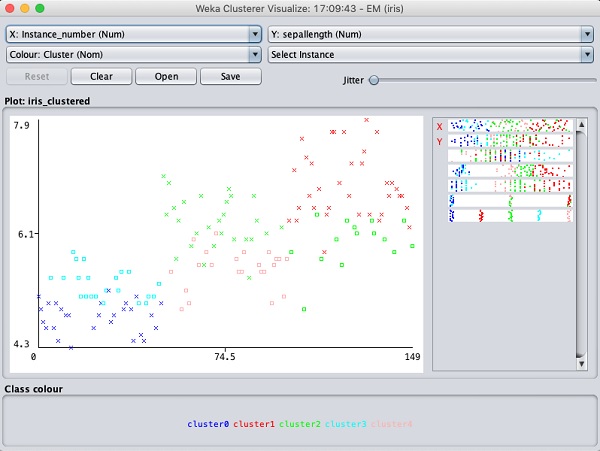
在分类的情况下,您会注意到正确识别和错误识别的实例之间的区别。您可以通过更改 X 和 Y 轴来分析结果。您可以在分类的情况下使用抖动来找出正确识别实例的浓度。可视化图中的操作和你在分类案例中学习的类似。
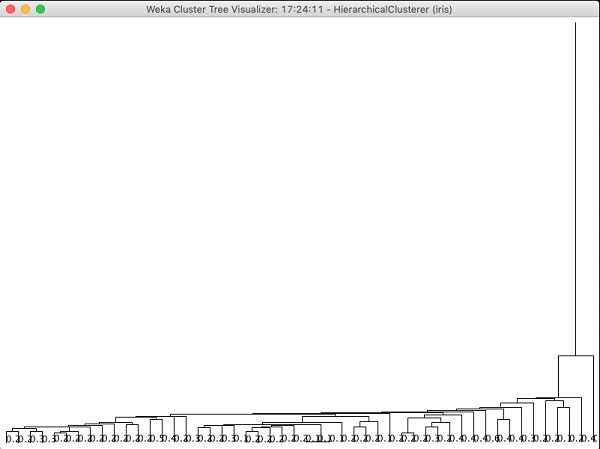
应用分层聚类器
为了展示 WEKA 的强大功能,现在让我们看看另一种聚类算法的应用。在 WEKA 资源管理器中,选择
HierarchicalClusterer 作为您的 ML 算法,如下面的屏幕截图所示-
选择
Cluster mode选择
Classes to cluster evaluation,然后点击
Start按钮。您将看到以下输出-
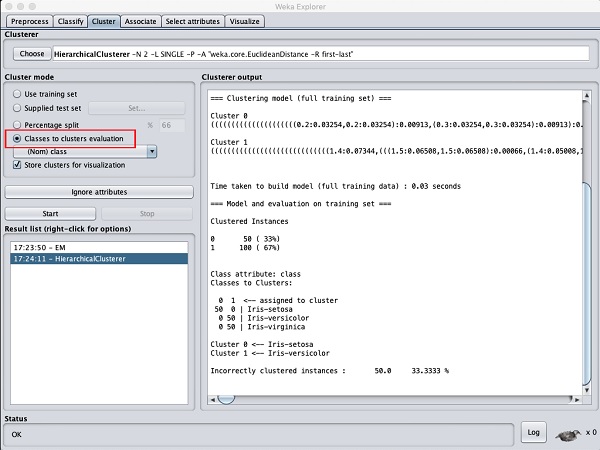
注意,在
结果列表中,列出了两个结果:第一个是EM结果,第二个是当前Hierarchical。同样,您可以将多个 ML 算法应用于同一数据集并快速比较它们的结果。
如果您检查此算法生成的树,您将看到以下输出-
在下一章中,您将学习
Associate 类型的机器学习算法。

