Spark 架构
Spark 架构
Spark 遵循主从架构。它的集群由一个主节点和多个从节点组成。
Spark 架构依赖于两个抽象:
弹性分布式数据集(RDD)
有向无环图(DAG)
弹性分布式数据集(RDD)
弹性分布式数据集是一组可以存储在工作节点内存中的数据项。在这里,
弹性: 在失败时恢复数据。
分布式: 数据分布在不同的节点上。
数据集: 数据组。
稍后我们将详细了解 RDD。
有向无环图(DAG)
有向无环图是一种有限有向图对数据执行一系列计算。每个节点是一个 RDD 分区,边是数据之上的一个变换。在这里,图指的是导航,而有向图和非循环图指的是导航方式。
让我们了解 Spark 架构。
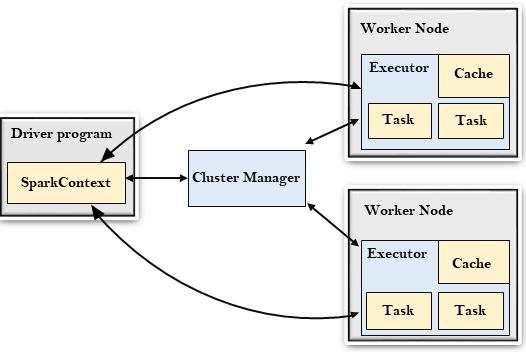
驱动程序
驱动程序是运行应用程序的 main() 函数并创建 SparkContext 的进程 对象。 SparkContext 的目的是协调 Spark 应用程序,在集群上作为独立的进程集运行。
要在集群上运行,SparkContext连接到不同类型的集群管理器,然后执行以下任务:-
它在集群中的节点上获取执行程序。
然后,它会将您的应用程序代码发送给执行程序。在这里,应用程序代码可以由传递给 SparkContext 的 JAR 或 Python 文件定义。
最后,SparkContext 将任务发送给执行程序以运行。
集群管理器
集群管理器的作用是跨应用程序分配资源。 Spark 足以在大量集群上运行。
它由各种类型的集群管理器组成,例如 Hadoop YARN、Apache Mesos 和 Standalone Scheduler。
这里,独立调度程序是一个独立的 Spark 集群管理器,有助于在一组空机器上安装 Spark。
工作节点
worker节点是slave节点
它的作用是在集群中运行应用程序代码。
执行者
执行程序是为工作节点上的应用程序启动的进程。
它运行任务并将数据保存在内存或磁盘存储中。
它将数据读写到外部源。
每个应用程序都包含其执行程序。
任务
将发送给一个执行者的工作单元。
