数据流测试
数据流测试
数据流测试用于分析程序中数据的流向。它是收集有关变量如何在程序中流动数据的信息的过程。它试图获取过程中每个特定点的特定信息。
数据流测试是一组测试策略,用于检查程序的控制流,以便根据事件的顺序探索变量的顺序。它主要关注分配给变量的值的点和使用这些值的点,通过集中在这两个点上,可以测试数据流。
数据流测试使用控制流图来检测可能中断数据流的不合逻辑的事情。由于以下原因,在值和变量之间关联时检测到数据流中的异常:
如果在没有初始化的情况下使用变量。
如果初始化的变量至少没有使用一次。
让我们通过一个例子来理解这一点:
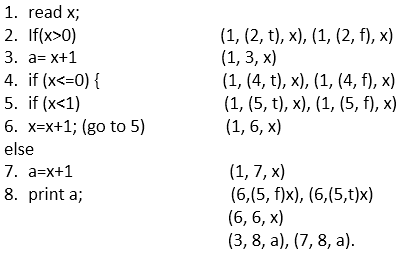
在这段代码中,我们总共有8条语句,我们将选择一条覆盖所有8条语句的路径。正如代码中很明显的那样,我们不能在一条路径中覆盖所有语句,因为如果语句 2 为真,则语句 4、5、6、7 未覆盖,如果语句 4 为真,则语句 2 和 3 未覆盖.
因此,我们采用两条路径来覆盖所有语句。
Output = 2
当我们首先将 x 的值设置为 1 时,它会在第 1 步读取并分配 x 的值(我们在路径中取了 1)然后出现语句 2(x>0(我们在路径中取了 2))这是真的,它出现在语句 3(a= x+1(我们在路径中取了 3))最后它出现在语句 8 中以打印x 的值(输出为 2)。
对于第二条路径,我们取 x 的值为 1
2. Set x=-1
Path = 1, 2, 4, 5, 6, 5, 6, 5, 7, 8
Output = 2
当我们将 x 的值设置为 ?1 时,首先,它会在第 1 步读取并分配 x 的值(我们采用1)然后进入第 2 步,这是错误的,因为 x 不大于 0(x>0 并且它们的 x=-1)。由于条件错误,它不会出现在语句 3 上并直接跳转到语句 4(我们在路径中取了 4)并且 4 为真(x<=0 并且它们的 x 小于 0)然后出现在语句 5(x<1(我们在路径中取了 5))这也是真的,所以它会出现在语句 6(x=x+1(我们在路径中取了 6))并且这里 x 增加了 1、
所以,
x 的值变为 0。现在转到语句 5(x<1(我们在路径中取 5)) 值为 0 并且 0 小于 1 所以,这是真的。来吧语句 6(x=x+1(我们在路径中取了 6))
那里 x 变成了 1 并再次转到语句 5(x<1(我们在路径中取了 5)),现在 1 不小于 1,所以,条件为假,它会来到 else 部分意味着语句 7(a=x+1 其中 x 的值为 1) 并将值分配给 a(a=2)。最后,它出现在语句 8 并打印值(输出为 2)。
为代码建立关联:
Associations
在关联中,我们列出了所有定义及其所有用途。
(1,(2, f), x),(1,(2, t), x),(1, 3, x),(1,(4, t), x) ,(1,(4, f), x),(1,(5, t), x),(1,(5, f), x),(1, 6, x),(1, 7, x),(6,(5, f)x),(6,(5,t)x),(6, 6, x),(3, 8, a),(7, 8, a)。
如何在数据流测试中建立关联
 (1,(2, t), x),(1,(2, f), x)- 这种关联是由语句 1(read x;) 和语句 2( If(x>0)) 其中 x 在第 1 行定义,并在第 2 行使用,因此 x 是变量。
(1,(2, t), x),(1,(2, f), x)- 这种关联是由语句 1(read x;) 和语句 2( If(x>0)) 其中 x 在第 1 行定义,并在第 2 行使用,因此 x 是变量。
语句 2 是合乎逻辑的,它可以为真或为假,这就是关联的原因以两种方式定义;一个是(1,(2, t), x) 表示真,另一个是(1,(2, f), x) 表示假。
(1, 3, x)- 这种关联由语句 1(读取 x;)和语句 3(a= x+1)构成,其中 x 在语句 1 中定义并用于语句 3. 它是一种计算用途。
(1,(4, t), x),(1,(4, f), x)- 这种关联是由语句 1(read x;) 和语句 4( If(x<=0)) 其中 x 在第 1 行定义并在第 4 行使用,因此 x 是变量。陈述 4 是合乎逻辑的,它可以为真或为假,这就是为什么以两种方式定义关联的原因,一种是(1,(4, t), x) 表示真,另一种是(1,(4, f), x)为假。
(1,(5, t), x),(1,(5, f), x)- 这种关联是由语句 1(read x;) 和语句 5( if(x<1)) 其中 x 在第 1 行定义,并在第 5 行使用,因此 x 是变量。
语句 5 是逻辑的,它可以为真或为假,这就是关联的原因以两种方式定义;一个是(1,(5, t), x) 表示真,另一个是(1,(5, f), x) 表示假。
(1, 6, x)- 这种关联是由语句 1(读取 x;)和语句 6(x=x+1)构成的。 x 在语句 1 中定义并在语句 6 中使用。它是一种计算用途。
(1, 7, x)- 这种关联是由语句 1(读取 x)和语句 7(a=x+1)构成的。 x 在语句 1 中定义,当语句 5 为假时,在语句 7 中使用。它是一种计算用途。
(6,(5, f) x),(6,(5, t) x)- 这种关联是由语句 6(x=x+1;) 和语句 5 构成的if(x<1) 因为 x 在语句 6 中定义并在语句 5 中使用。 语句 5 是合乎逻辑的,它可以为真或为假,这就是为什么以两种方式定义关联的原因之一是(6,(5, f) x) 表示真,另一个是(6,(5, t) x) 表示假。这是一个预测用途。
(6, 6, x)- 这种关联与语句 6 相关,语句 6 使用变量 x 的值,然后定义 x 的新值。
x=x+1
x=(-1+1)
语句 6 使用变量 x 的值,即?1,然后定义 x 的新值 [x=(-1+1 ) = 0] 即 0。
(3, 8, a)- 这种关联由语句 3(a= x+1) 和语句 8 构成,其中变量 a 在语句 3 中定义并在语句 8 中使用。
(7, 8, a)- 这种关联由语句 7(a=x+1) 和语句 8 构成,其中变量 a 在语句 7 中定义并在语句 8 中使用。
定义,c-use,p-use,c-use some p-use coverage,p-use some c-use coverage in data flow testing
接下来的任务是将Definition中的所有关联分组,c-use,p-use,c-use一些p-usecoverage,p-use一些c-usecoverage类别。
见下面的代码:
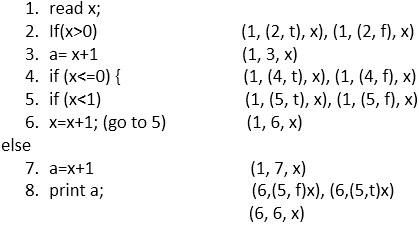
所以,这些是包含定义,谓词使用(p-use),计算使用(c-use)的所有关联
(1,(2, f), x),(1,(2, t), x),(1, 3, x),(1,(4, t), x),(1,(4, f), x),(1,(5, t), x),(1,(5, f), x),(1, 6, x),(1, 7, x),(6,(5, f) )x),(6,(5,t)x),(6, 6, x),(3, 8, a),(7, 8, a),(3, 8, a),(7, 8、a)
定义
变量的定义是当值绑定到变量时变量的出现。在上面的代码中,值在第一个语句中被绑定,然后开始流动。
If(x>0) 是语句 2,其中 x 的值与其绑定。
语句 2 的关联是(1,(2, f), x),(1,(2, t.)
a= x+1 是以 x 的值为界的语句 3
语句 3 的关联是(1, 3, x)
所有定义覆盖
(1,(2, f), x),(6,(5, f) x),(3, 8, a),(7, 8, a).
谓词使用(p-use)
如果一个变量的值被用来决定一个执行路径被视为谓词使用(p-use)。在控制流语句中,有两个
Statement 4 if(x<=0) 是谓词使用,因为它可以是谓词为真或假。如果为真则 if(x<1),6x=x+1;否则会执行执行路径,否则会执行路径。
计算使用(c-use)
如果使用变量的值来计算一个用于输出或定义另一个变量的值。
语句 3 a= x+1(1, 3, x)
语句 7 a =x+1(1, 7, x)
语句 8 打印(3, 8, a),(7, 8, a)。
这些是计算用途,因为x的值用于计算,a的值用于输出。
所有c-use覆盖
(1, 3, x),(1, 6, x),(1, 7, x),(6, 6, x),(6, 7, x),(3, 8, a) ,(7, 8, a)。
所有c-use一些p-use覆盖
(1, 3, x),(1, 6, x),(1, 7 , x),(6, 6, x),(6, 7, x),(3, 8, a),(7, 8, a)。
所有p-use一些c-use覆盖
(1,(2, f), x),(1,(2, t) , x),(1,(4, t), x),(1,(4, f), x),(1,(5, t), x),(1,(5, f), x ),(6,(5, f), x),(6,(5, t), x),(3, 8, a),(7, 8, a).
之后收集这些组,(通过检查每个点是否至少使用了一次变量)测试人员可以看到所有语句和变量被使用。代码中没有使用但存在的语句和变量,从代码中删除。

