ES 聚合API
Elasticsearch 聚合API
Elasticsearch 提供聚合 API,用于数据的聚合。聚合框架提供基于搜索查询的聚合数据。简而言之,聚合框架收集由搜索查询选择并提供给用户的所有数据。它包含几个构建块,可帮助构建复杂的数据摘要。聚合会生成 Elasticsearch 中可用的分析信息。
以下是一些需要注意的聚合要点:
聚合可以组合在一起以构建复杂的数据摘要。
它可以被视为一个工作单元,它通过一组在 elasticsearch 中可用的文档生成分析信息。
它基本上基于构建块。
聚合函数与 SQL AVERAGE 和 GROUP BY COUNT 函数相同。
在 elasticsearch 中使用聚合时,我们可以对任何数字字段执行 GROUP BY 聚合,但我们必须输入 keyword(关键字就像索引)或 fielddata = true 用于文本字段。
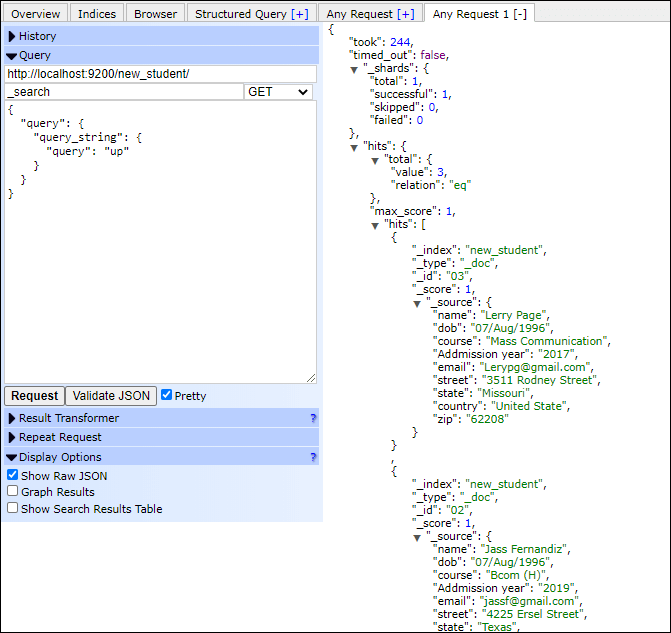
看下图,聚合的样子:
聚合语法
聚合的基本结构-
"aggregation" : {
"<aggregation_name1>" : {
"<aggregation_type>" : {
<aggregation_body>
"field " : "document_field_name"
}
[ , "meta" : { [<meta_data_body>] } ]?
[ , "aggregation" : { [<sub_aggregation>] + } ]?
}
[ , "<aggregation_name_2>" : { . . . } ]*
}
我们可以一次使用多个聚合。
聚合-是JSON 保存要计算的聚合。您还可以使用 aggs 关键字代替聚合。
aggregation_name- 每个聚合都有一个由用户定义的逻辑名称。例如,使用 avg_price 计算平均价格。
aggregation_type- 这是一种聚合类型,因为每个聚合都有一个特定的名称。
Aggregation_body- 每种聚合类型都由自己的聚合主体组成,这取决于聚合的性质。
field- 是字段关键字。
document_field_name- 它是文档中目标列的名称。
聚合类型
在 Elasticsearch 中,有几种类型的聚合可用,其中每个聚合都有自己的目的和输出。为简化起见,将它们归纳为4大族,分别如下-
指标聚合
分桶聚合
矩阵聚合
管道聚合
指标聚合
指标聚合是一种聚合,负责对指标进行持续跟踪。度量聚合根据聚合文档的字段值计算矩阵。它还有助于计算一组文档的度量。
一些聚合生成数字度量,它们是-
单值数值度量聚合,即平均聚合或
多值数值指标聚合,即统计数据
Bucketing
Bucketing 是一个聚合家族,负责构建桶。它不计算指标聚合等字段的指标。在这个聚合中,每个桶都与一个键和一个文档相关联。桶聚合用于分组或创建数据桶。这些数据桶可以基于现有的字段、范围和自定义过滤器等进行制作。
矩阵聚合
Metrix 聚合是一种对多个对象进行操作的聚合领域。它适用于多个字段,并从值中生成一个矩阵结果,该结果是从请求文档字段中提取的。 Matrix 不支持脚本。
Pipeline
顾名思义,它从其他聚合的输出中获取输入。换句话说,我们可以说,-管道聚合负责聚合其他聚合的输出。
所有这些聚合都被进一步分类,特别是桶、管道和指标聚合。
五个重要的聚合
下面举例说明elasticsearch的一些基本聚合。
平均聚合
术语聚合
基数聚合
统计聚合v
平均聚合
平均聚合用于计算索引中任何数字字段的平均值。创建查询时在查询中指定聚合名称 avg。查看以下示例以查找字段 "fees" 的平均值:
Copy Code
POST student1/ _search/
{
"aggs": {
"avg_fees": {
"avg" : {
"field": "fees"
}
}
}
}
通过执行上面的代码,我们将得到文档中存在的费用的平均值。
响应
你将得到如下输出以下回复。
{
"took": 1251,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"index": "student1",
"type": "_doc",
"id": "01",
"score": 1,
"_source": {
"name ": "Denial Parygen",
"dob": "07/Aug/1998",
"course": "Mass Communication",
"Addmission year": "2018",
"email": "denial@gmail.com",
"street": "3511 Rodney Street",
"state": "Missouri",
"country": "United States",
"zip": "62208",
"fees": "24800"
}
},
{
"index": "student1",
"type": "_doc",
"id": "03",
"score": 1,
"_source": {
"name ": "Bob Hana",
"dob": "13/Sep/1998",
"course": "BFA",
"Addmission year": "2019",
"email": "bob@gmail.com",
"street": "724 Monroe Street",
"state": "Hauston",
"country": "United States",
"zip": "77063",
"fees": "18900"
}
},
{
"index": "student1",
"type": "_doc",
"id": "02",
"score": 1,
"_source": {
"name ": "Jass Fernandiz",
"dob": "07/Aug/1996",
"course": "Bcom (H)",
"Addmission year": "2019",
"email": "jassf@gmail.com",
"street": "4225 Ersel Street",
"state": "Texas",
"country": "United States",
"zip": "76011",
"fees": "22900"
}
}
]
},
"aggregations": {
"avg_fees": {
"value": "22200"
}
}
}
如果该字段缺失
如果该字段在文档中不存在(您正在计算平均值),默认情况下它会被忽略并为空值被返回。您可以在聚合中添加缺失字段("missing": 0) 以将缺失值视为默认值。执行以下代码:
复制代码
POST new_student/ _search/
{
"aggs": {
"avr_fees": {
"avg" : {
"field": "fees",
"missing": 0
}
}
}
}
Terms Aggregation
terms 聚合负责按字段值生成桶。通过选择一个字段(如姓名、入学年份等),它会生成桶。创建查询时指定查询中的聚合名称。
执行以下代码以搜索按入学年份字段分组的值:
复制代码
POST student/ _search/
{
"size": 0,
"aggs": {
"group_by_Addmission year": {
"terms" : {
"field": "Addmission year.keyword"
}
}
}
}
通过执行上面的代码,输出将按入学年份作为一个组返回。
响应
您将得到类似的输出以下回复。
{
"took": 179,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [ ]
},
"aggregations": {
"group_by_Addmission year": {
"student1",
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key ": "2019",
"doc_count": 2
},
{
"key": "2018",
"doc_count": 1
}
]
}
}
}
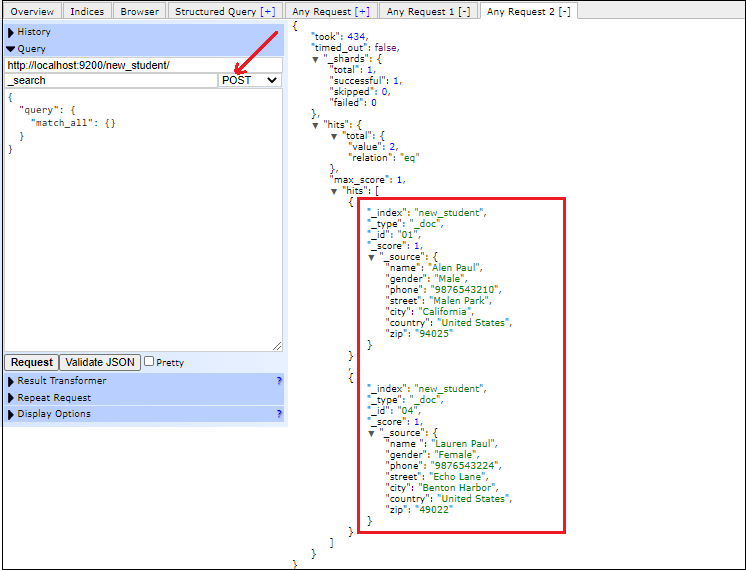
上面的查询和响应在elasticsearch-head插件中看起来像下面的截图:
Cardinality Aggregation
为一个字段找到一个唯一值是一个常见的要求。基数聚合有助于为任何特定字段找到唯一值。它有助于确定索引中存在的唯一元素的数量。
在创建查询时指定查询中的聚合名称。执行以下代码以查找字段的唯一值数量:
复制代码
POST student/ _search/
{
"size": 0,
"aggs": {
"unique_fees": {
"cardinality" : {
"field": "fees"
}
}
}
}
通过执行上述代码,输出将返回 fees 字段的唯一值总数 student 索引。
响应
您将得到如下响应的输出。
{
"took": 85,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [ ]
},
"total": {
"value": 3,
"relation": "eq":
}
"max_score ": null
"hits": [ ]
},
"aggregations": {
"unique_fees": {
"value": 3
}
]
}
}
}
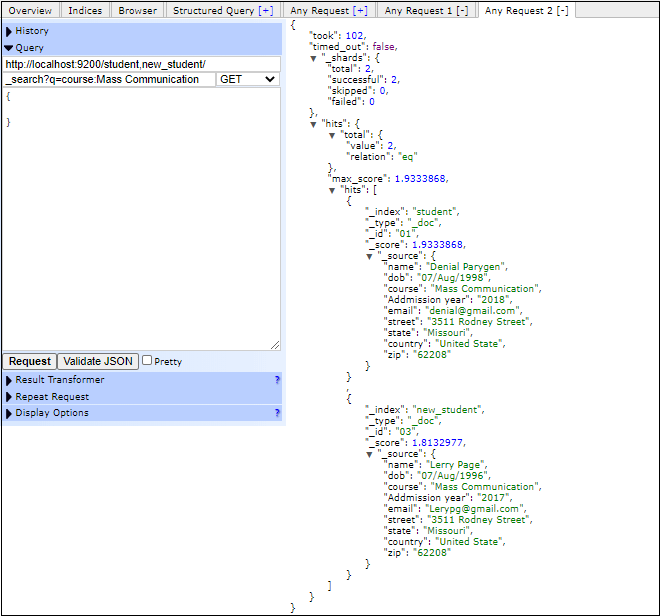
看下面的截图,查询如何在elasticsearch head插件中运行并响应-
Stats Aggregation
Stats Aggregation 代表statistics,是一种多值的数值矩阵聚合。它有助于在一次拍摄中生成 sum、avg、min、max 和 count。当聚合文档很大时,此聚合允许生成特定数字字段的所有统计信息。查询结构与其他聚合相同。
执行以下代码,单次查找sum、avg、min、max和count:
复制代码
POST student/ _search/
{
"aggs": {
"stats_fees": {
"extended_stats" : {
"field": "fees"
}
}
}
}
响应
通过执行上面的代码,你会得到如下响应的输出。
{
"took": 75,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [ ]
},
"aggregation": {
"stats_fees": {
"count": 3,
"min": 18900,
"max": 24800,
"avg": 22200,
"sum": 66600,
"sum_of_square": 1496660000,
"variance": 9070000,
"std_deviation": 3011.644,
"std_deviation_bounds": {
"upper": 2600,
"lower": 700
}
}
}
}
过滤聚合
过滤聚合有助于过滤单个桶中的文档。它的主要目的是通过过滤文档向其用户提供最佳结果。我们举个例子,根据"费用"和"入学年份"过滤文档。这将返回与查询中指定的条件匹配的文档。您可以使用任何您想要的字段来过滤文档。
执行以下代码以过滤与您在查询中指定的条件匹配的文档:
复制代码
POST student/ _search/
{
"query": {
"bool": {
"filter": [
{ "term": { "fees": "22900" } },
{ "term": { "Addmission year": "2019" } },
]
}
}
}
响应
通过执行上面的代码,你会得到如下响应的输出。
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0,
"hits": [ ]
{
"index": "student",
"type": "_doc",
"id": "02",
"score": 1,
"_source": {
"name ": "Jass Fernandiz",
"dob": "07/Aug/1996",
"course": "Bcom (H)",
"Addmission year": "2019",
"email": "jassf@gmail.com",
"street": "4225 Ersel Street",
"state": "Texas",
"country": "United States",
"zip": "76011",
"fees": "22900"
}
}
]
}
}
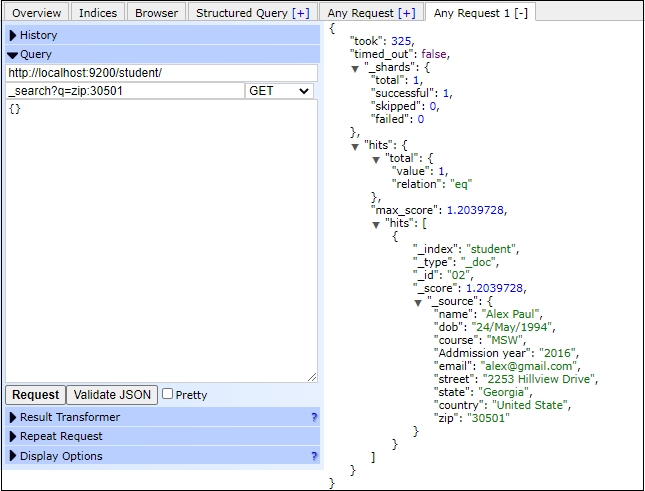
上面的查询和响应在elasticsearch head插件中看起来像下面的截图-