ES 摄取节点
Elasticsearch Ingest Node
有时需要在索引之前转换文档。因此,您需要使用摄取节点在实际索引发生之前对文档进行预处理。 例如,如果我们想重命名一个字段并为其建立索引或从文档中删除一个字段,所有这些操作都由 Ingest 节点处理。在集群中,所有节点都具有摄取能力,但必须对其进行自定义才能由特定节点进行处理。我们需要按照一些步骤来摄取节点。
涉及步骤
摄取节点的工作基本上涉及两个步骤-
创建管道
创建文档
我们将详细讨论这两个步骤。
创建管道
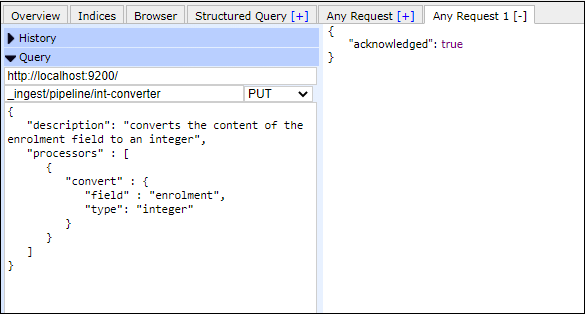
首先,我们需要创建一个管道,其中包含处理器。我们将以管道创建为例,将注册字段的内容转换为整数类型。为此,请在 Elasticsearch 插件中运行以下代码以执行管道-
复制代码
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the enrolment field to an integer",
"processors": [
{
"convert": {
"field": "enrolment",
"type": "integer"
}
}
]
}
响应
如果得到与下面输出相同的响应,则代码执行成功。
{
"acknowledged": true,
}
屏幕截图
创建文档
管道创建后,下一步是创建文档。因此,我们将使用管道转换器创建一个文档。执行以下代码——
复制代码
PUT /list/_doc/1?pipeline=int-converter
{
"enrolment": "39",
"name": "Ileana",
"city": "Noida"
}
响应
如果您得到与以下输出相同的响应,则代码执行成功。
{
"index": "list",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0,
},
"_seq_no": 0,
"_primary_term": 1,
}
屏幕截图
现在,我们将从上面创建的索引中获取文档。为此,请使用如下所示的 GET 命令-
Copy Code
响应
如果得到与下面输出相同的响应,则代码执行成功。
{
"index": "list",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"city": "Noida",
"name": "Ileana",
"enrolment": 39,
}
}
在这里,在上面的输出中,您可以看到注册字段已转换为整数。
没有流水线
没有创建流水线,整数类型值不会转换为整数。看看下面不使用管道创建索引的例子。
复制代码
PUT /list/_doc/2
{
"enrolment": "25"
"name": "Alex",
"city": "Gurugram"
}
响应
如果得到与下面输出相同的响应,则代码执行成功。
{
"index": "list",
"_type": "_doc",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0,
},
"_seq_no": 0,
"_primary_term": 1,
}
获取文档
复制代码
响应
通过运行上面的代码,如果得到与下面输出相同的响应,则代码执行成功。
{
"index": "list",
"_type": "_doc",
"_id": "2",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"city": "Gurugram",
"name": "Alex",
"enrolment": "25"
}
}
在这里,在上面的输出中,您可以看到注册字段值 "25" 尚未转换为整数。它是一个打印在引号""之间的字符串,没有流水线。

