ES 分页
Elasticsearch Pagination
在开始在 Elasticsearch 中进行分页并知道如何进行之前,了解什么是分页很重要。所以,让我们先从分页开始。
每次我们在网上搜索一些东西时,它都会返回很多结果。这些结果可能是成百上千,有时甚至是十万,分布在几页上。每个页面有多个记录。这种机制称为分页。分页有助于用户轻松高效地查找所需信息。
通常,每个页面由 10 条记录组成,但这不是限制。您可以设置每页要显示的记录数。下图显示了分页的样子,以便您能够很好地理解它。

分页是一系列具有相似内容的页面。它也称为分页,可帮助用户直接移动到任何页面。因此,他们不需要向下滚动页面太长时间。它节省了用户的宝贵时间。大多数情况下,分页放置在页面底部。但是,我们也可以将其放置在我们想要的任何位置,例如-页面顶部。 请注意我们可以使用滚动分页。
Elasticsearch 中的分页
Elasticsearch 允许用户执行分页。这很容易做到。在 Elasticsearch 中,有两个属性 from 和 size,它们有助于非常有效地执行分页。这些参数如下:
From-该属性用于指定每个页面开始搜索索引中记录的起始点。意味着它指定了 Elasticsearch 应该从索引中的哪条记录开始搜索。在此,您可以定义从头开始跳过的项目数。
Size- 该属性用于指定每页要搜索的记录数。这意味着在这个属性中设置了返回多少结果。
因此,在分页的帮助下,我们能够挑选出特定数量的记录返回给用户。
如何在 Elasticsearch 中进行分页
在 Elasticsearch 中,我们可以借助 from 和 进行分页>size 属性,如上所述。这将帮助您从索引中获取特定数量的结果并将它们返回给用户。但是,这些 from 和 size 参数仅适用于 10k 搜索结果。
让我们以查询示例在 Elasticsearch 中进行分页-
GET /reasoning/
_search
{
"query": {
"match_all": { }
},
"from": 0,
"size": 15
}
这里reasoning是索引的名字,_search是Elasticsearch API。根据这个查询,它将返回推理索引中的 15 条记录。
很明显,每种技术都有一些缺点和优点。 Elasticsearch 分页也有一个小问题。当对 Elasticsearch 索引执行搜索请求时,如果我们得到超过 10000 个结果的列表。 from + size 索引不能大于 index.max-result-window. 其默认值为创建索引时设置为10000。
我们有解决方案,您可以使用scroll API 或search_after 参数来处理此问题。如果您需要继续,请使用 search_after。另一方面,如果您需要转储包含超过 1 万个文档的整个索引,请使用滚动 API。
我们将详细讨论这两种解决方案:
如果列表超过10000项如何解决?
Elasticsearch有解决方案,如果列表超过10k项,如下-
1、 Elasticsearch 的Scroll API
Elasticsearch 为其用户提供了scroll API 来处理此类问题。如果请求很大并且延迟不是那么重要,我们可以使用滚动 API。这意味着如果没有时间问题并且请求也很大,scroll API 很有用。
scroll API 推荐用于深度滚动。但是,由于此解决方案,网络给出了很多警告。尽管如此,我们还是实施了这个解决方案。
预计它会很慢,执行可能需要大约 10 分钟。此外,它也是一个昂贵的解决方案,因为 Elasticsearch 在每次迭代之间保持状态。因此,它不是实时用户请求的最佳解决方案。综上所述,对于实时请求是不可接受的,并且滚动上下文也很昂贵。请参见下面的示例:
示例
我们必须发送初始请求才能开始滚动。通常,此请求会在服务器上启动搜索上下文。在这个查询请求中,你需要在scroll参数中指定滚动时间(即scroll=TTL),表示它存活的时间。此查询请求将使上下文保持活动状态 2 分钟。
GET /aptitude
_search?scroll=2m
{
"size": 50,
"query": {
"term": { "subject": "reasoning" }
}
}
2.使用search_after参数
借助from和size参数,我们可以执行分页经济高效。但是当达到深度分页时,成本上升太多。 scroll API 适用于大型请求,但没有响应时间限制。因此,它不适合实时用户请求。
Elasticsearch 提供了一个search_after 参数,该参数适合实时使用请求。 search_after 参数提供一个实时游标。它不用于跳转到随机页面,它有助于并行滚动多个查询。请注意,搜索请求占用的堆内存和时间相当于 from + size。请参阅以下示例:
GET /reasoning/
_search
{
"size": 15,
"query": {
"match_all": { }
},
"sort": [
{ "date": "desc" }
],
"search_after": [14635388570]
}
3.增加 index.max_result_window 的值
基本上,这个值(index.max_result_window) 有助于在大型查询中保留 Elasticsearch 集群内存。通过增加此值,集群延迟可能会崩溃。
Elasticsearch 不允许用户在 index.max_result_window 设置之外进行分页。这不是限制,而是防止深度分页的保护措施。默认情况下,其值为 10000。因此,from + size 应小于此值。
4.将列表限制为 10k 文章
如果需要对超过 10k 的结果进行分页,此请求可能不够精确。因为对超过 10k 的结果进行分页是不好的。 Elasticsearch 不仅仅是一个搜索引擎。为了SEO的目的,有些文章必须显示完整的历史记录,这些文章超过了 10k 篇。
已实施的解决方案
让我们借助流程图来了解这里描述了两种解决方案-
如果from + size 的值小于或等于 10000(max_result_window 的默认值),则照常执行经典的 Elasticsearch 查询。
否则,使用预先计算的页面并根据上一页的最后一篇文章执行search_after查询。
见下图:
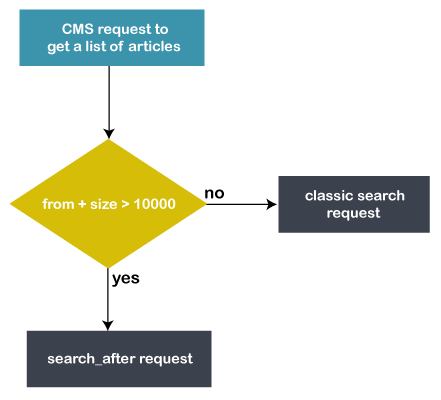
前10k以内的页面物品是新鲜的,因为它们是按需计算的。而其他页面则没有预期的那么新鲜。这些页面是静态的和预先计算的,但可以用于 SEO 目的。为此执行查询请求。

