Spark组件
Spark项目由不同类型的紧密集成的组件组成。 Spark的核心是可以调度,分发和监视多个应用程序的计算引擎。
让我们详细了解每个Spark组件。
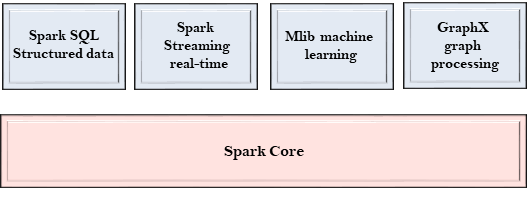
Spark Core
Spark Core是Spark的心脏,并执行核心功能。
它包含用于任务计划,故障恢复,与存储系统交互和内存管理的组件。
Spark SQL
Spark SQL构建在Spark Core的顶部。它提供了对结构化数据的支持。
它允许通过SQL(结构化查询语言)以及Apache Hive SQL变体(称为HQL(Hive查询语言))来查询数据。
它支持JDBC和ODBC连接,该连接在Java对象与现有数据库,数据仓库和商业智能工具之间建立了联系。
它还支持各种数据源,例如Hive表,Parquet和JSON。
Spark Streaming
Spark Streaming是一个Spark组件,它支持流数据的可伸缩和容错处理。
它使用Spark Core的快速调度功能来执行流分析。
它以小批量的形式接受数据,并对该数据执行RDD转换。
其设计可确保为流数据编写的应用程序可以重复使用,而无需修改就可以分析一批历史数据。
由Web服务器生成的日志文件可以视为数据流的实时示例。
MLlib
MLlib是一个机器学习库,其中包含各种机器学习算法。
其中包括相关性和假设检验,分类和回归,聚类以及主成分分析。
它比Apache Mahout使用的基于磁盘的实现快九倍。
GraphX
GraphX是一个用于处理图形和执行图形并行计算的库。
它有助于创建一个有向图,其中每个顶点和边都具有任意属性。
要操作图,它支持各种基本运算符,例如子图,联接顶点和聚合消息。

