Hive 架构
以下体系结构说明了向Hive提交查询的流程。
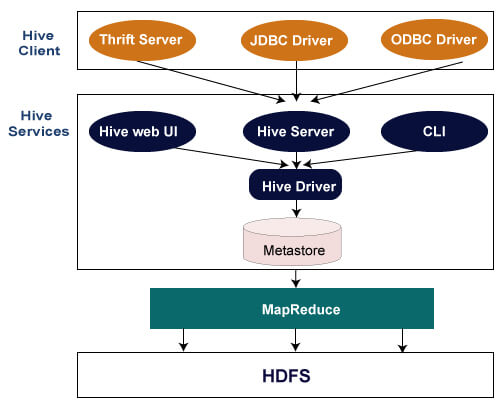
Hive客户端
Hive允许使用各种语言(包括Java,Python和C ++)编写应用程序。它支持不同类型的客户端,例如:-
Thrift服务器-这是一种跨语言服务提供商平台,可为来自所有支持Thrift的编程语言的请求提供服务。
JDBC驱动程序-用于在hive和Java应用程序之间建立连接。 JDBC驱动程序存在于org.apache.hadoop.hive.jdbc.HiveDriver类中。
ODBC驱动程序-它允许支持ODBC协议的应用程序连接到Hive。
Hive服务
以下是Hive提供的服务:-
Hive CLI-Hive CLI(命令行界面)是一个外壳,我们可以在其中执行Hive查询和命令。
Hive Web用户界面-Hive Web UI只是Hive CLI的替代方法。它提供了一个基于Web的GUI,用于执行Hive查询和命令。
Hive MetaStore-这是一个中央存储库,用于存储仓库中各种表和分区的所有结构信息。它还包括列的元数据及其类型信息,用于读写数据的序列化器和反序列化器以及存储数据的相应HDFS文件。
Hive服务器-称为Apache Thrift服务器。它接受来自不同客户端的请求,并将其提供给Hive Driver。
Hive驱动程序-它接收来自不同来源的查询,例如Web UI,CLI,Thrift和JDBC/ODBC驱动程序。它将查询转移到编译器。
Hive编译器-编译器的目的是解析查询并对不同的查询块和表达式执行语义分析。它将HiveQL语句转换为MapReduce作业。
Hive执行引擎-优化器以map-reduce任务和HDFS任务的DAG形式生成逻辑计划。最后,执行引擎按照传入任务的依赖关系顺序执行传入的任务。
