MapReduce字符计数
在MapReduce字符计数示例中,我们找出每个字符的频率。在这里,Mapper的作用是将键映射到现有值,而Reducer的作用是聚合公用值的键。因此,一切都以键值对的形式表示。
先决条件
Java安装-使用以下命令检查是否已安装Java。
java-version
Hadoop安装--使用以下命令检查是否已安装Hadoop。
hadoop版本
如果您的系统中未安装任何软件,请单击下面的链接进行安装。
www.lidihuo.com/hadoop-installation
执行MapReduce字符计数示例的步骤
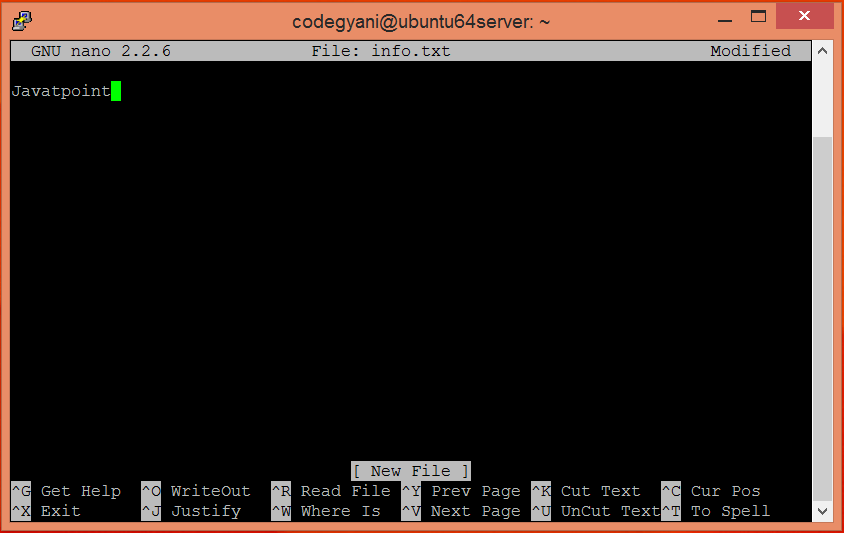
在本地计算机上创建一个文本文件,然后在其中写入一些文本。
$ nano info.txt
 检查写在info.txt文件中的文本。
检查写在info.txt文件中的文本。
$ cat info.txt
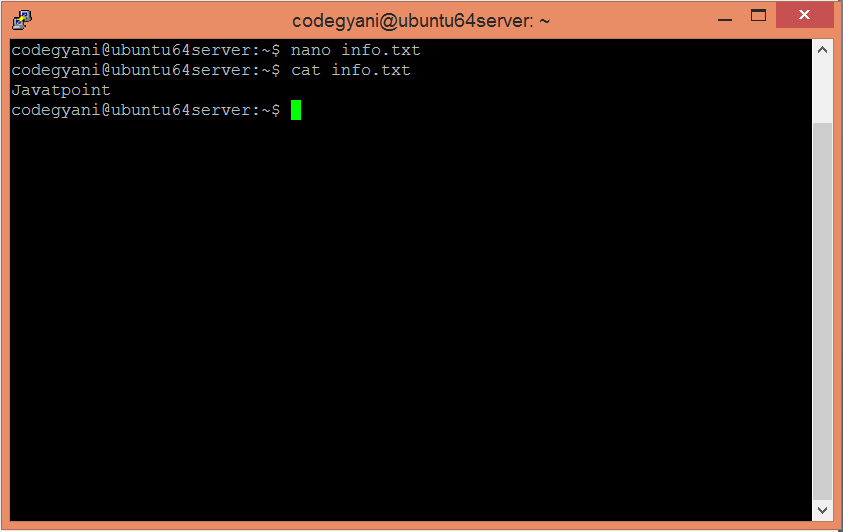
在此示例中,我们找出每个字符的频率值存在于此文本文件中。
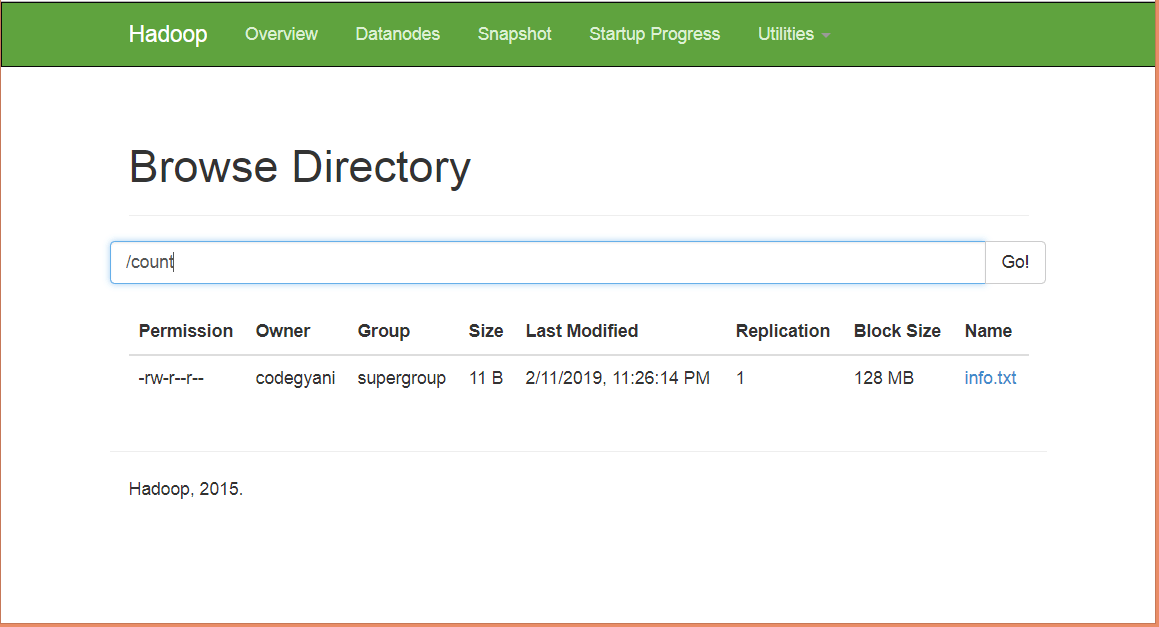
在HDFS中创建一个目录,用于保存文本文件。
$ hdfs dfs-mkdir/count
将HDFS上的info.txt文件上传到特定目录中。
$ hdfs dfs-put/home/codegyani/info.txt/count
 使用Eclipse编写MapReduce程序。
使用Eclipse编写MapReduce程序。
文件: WC_Mapper.java
package com.lidihuo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class WC_Mapper extends MapReduceBase implements Mapper<LongWritable,Text,Text,IntWritable>{
public void map(LongWritable key, Text value,OutputCollector<Text,IntWritable> output,
Reporter reporter) throws IOException{
String line = value.toString();
String tokenizer[] = line.split("");
for(String SingleChar : tokenizer)
{
Text charKey = new Text(SingleChar);
IntWritable One = new IntWritable(1);
output.collect(charKey, One);
}
}
}
文件: WC_Reducer.java
package com.lidihuo;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class WC_Reducer extends MapReduceBase implements Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,OutputCollector<Text,IntWritable> output,
Reporter reporter) throws IOException {
int sum=0;
while (values.hasNext()) {
sum+=values.next().get();
}
output.collect(key,new IntWritable(sum));
}
}
文件: WC_Runner.java
package com.lidihuo;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WC_Runner {
public static void main(String[] args) throws IOException{
JobConf conf = new JobConf(WC_Runner.class);
conf.setJobName("CharCount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(WC_Mapper.class);
conf.setCombinerClass(WC_Reducer.class);
conf.setReducerClass(WC_Reducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf,new Path(args[0]));
FileOutputFormat.setOutputPath(conf,new Path(args[1]));
JobClient.runJob(conf);
}
}
下载源代码。
创建该程序的jar文件并将其命名为 charcountdemo.jar。
运行jar文件
hadoop jar/home/codegyani/charcountdemo.jar com.lidihuo.WC_Runner/count/info.txt/char_output
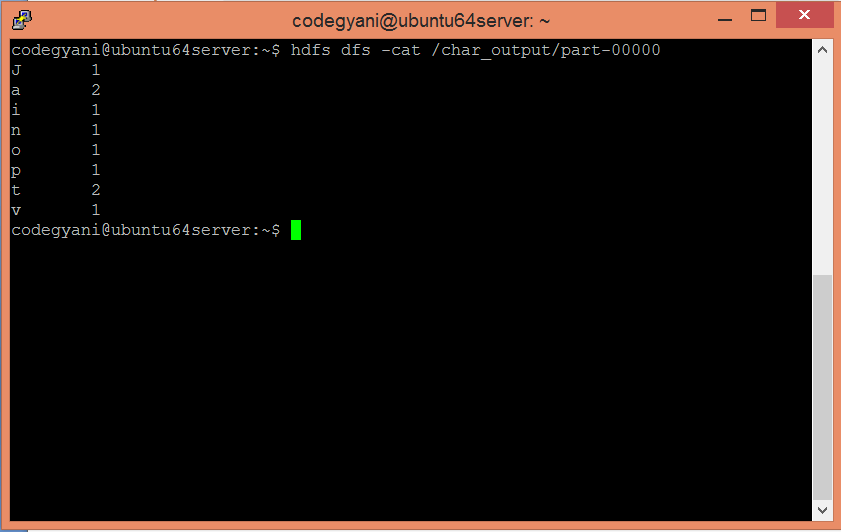
输出存储在/char_output/part-00000
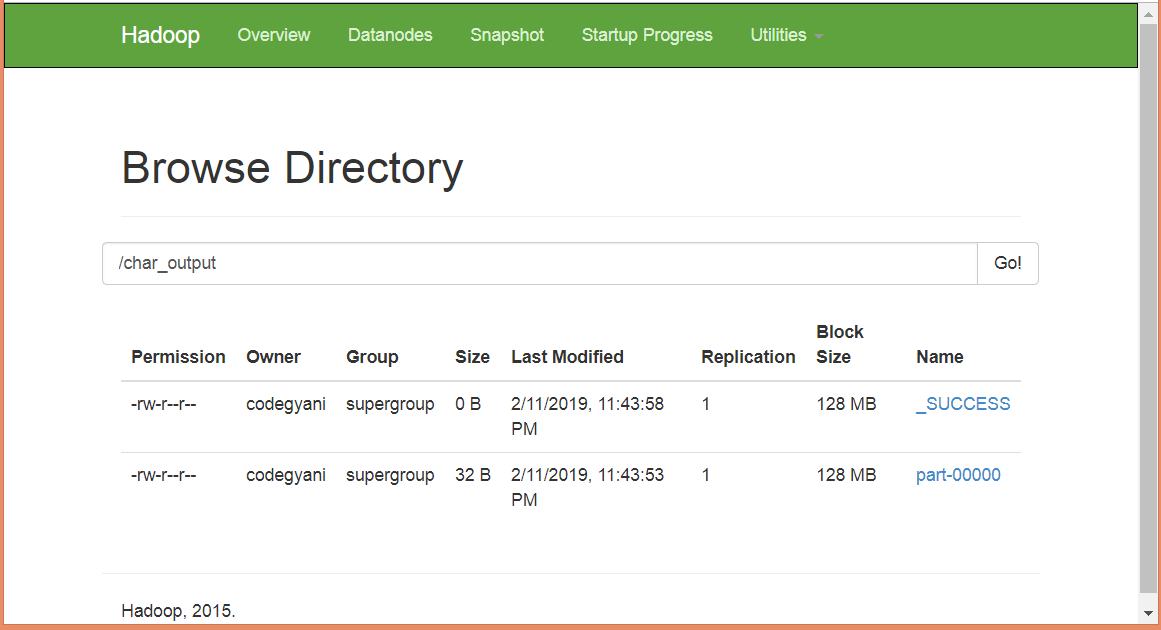 现在执行命令以查看输出。
现在执行命令以查看输出。
hdfs dfs-cat/r_output/part-00000