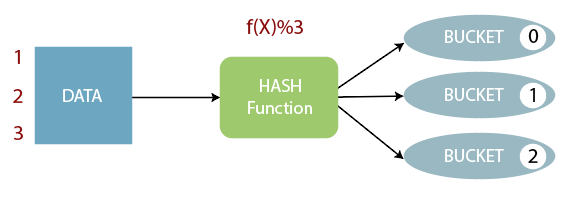
 存储桶的概念基于哈希技术。
在这里,计算当前列值的模块和所需的存储桶数(假设F(x)%3)。
现在,基于结果值,数据将存储到相应的存储桶中。
存储桶的概念基于哈希技术。
在这里,计算当前列值的模块和所需的存储桶数(假设F(x)%3)。
现在,基于结果值,数据将存储到相应的存储桶中。
hive> use showbucket;
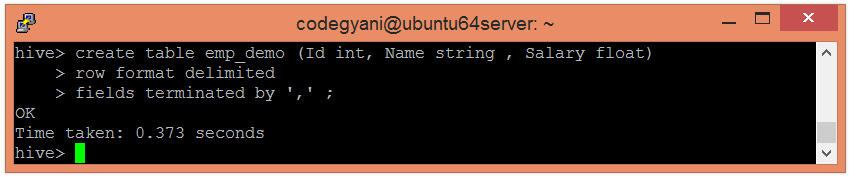
 创建一个虚拟表来存储数据。
创建一个虚拟表来存储数据。
hive> create table emp_demo (Id int, Name string , Salary float) row format delimited fields terminated by ',' ;
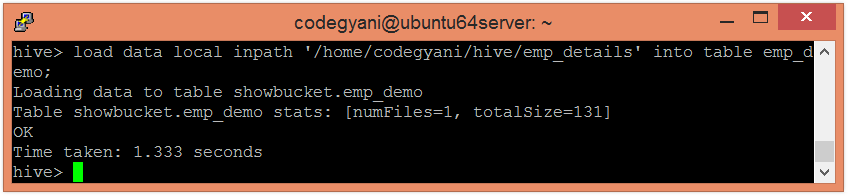
 现在,将数据加载到表中。
现在,将数据加载到表中。
hive> load data local inpath '/home/codegyani/hive/emp_details' into table emp_demo;
 使用以下命令启用存储桶:-
使用以下命令启用存储桶:-
hive> set hive.enforce.bucketing = true;
hive> create table emp_bucket(Id int, Name string , Salary float) clustered by (Id) into 3 buckets row format delimited fields terminated by ',' ;
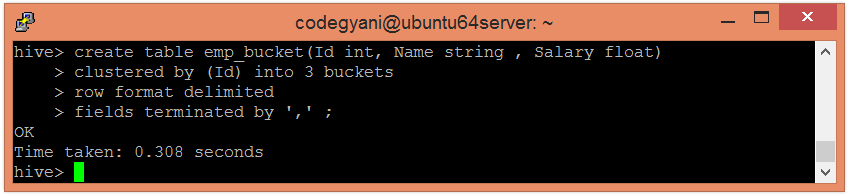 现在,将虚拟表的数据插入存储桶的表中。
现在,将虚拟表的数据插入存储桶的表中。
hive> insert overwrite table emp_bucket select * from emp_demo;
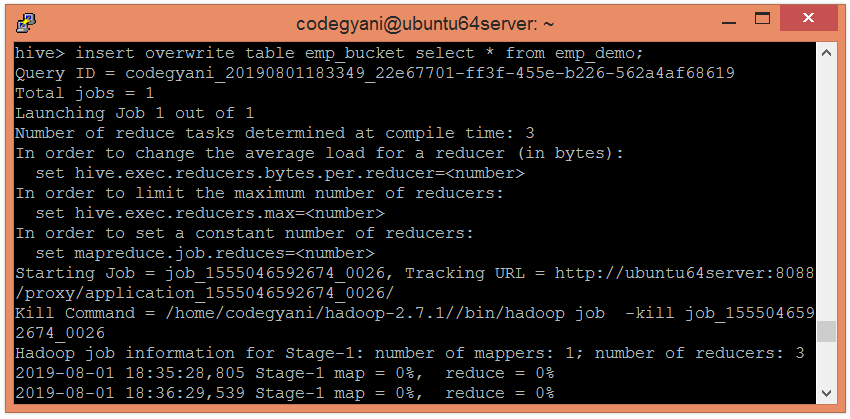
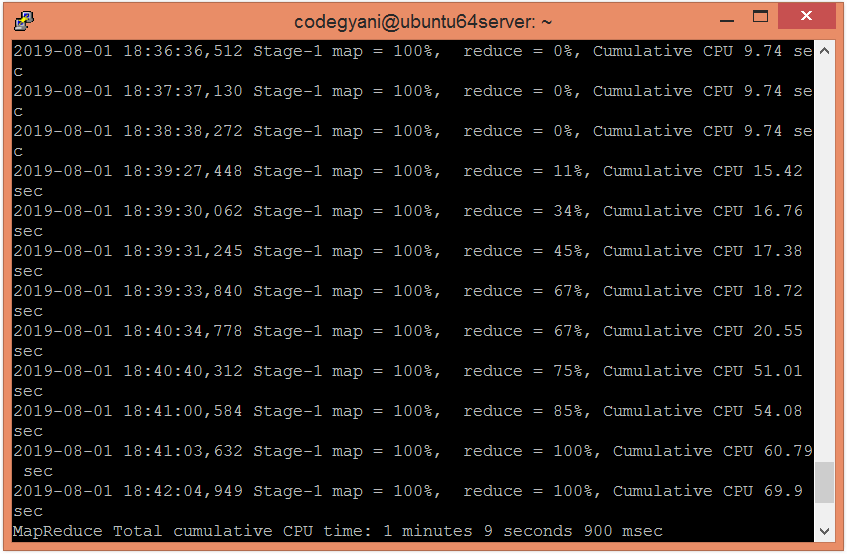
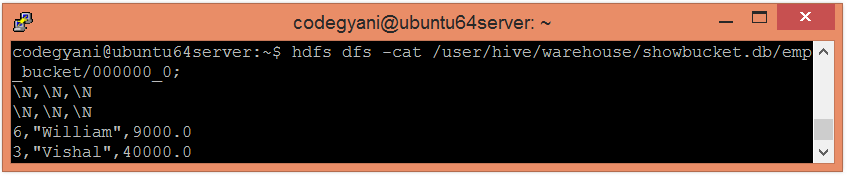
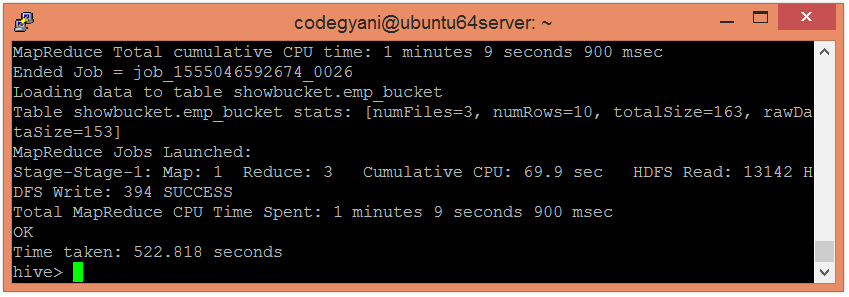 在这里,我们可以看到数据分为三个存储桶。
在这里,我们可以看到数据分为三个存储桶。
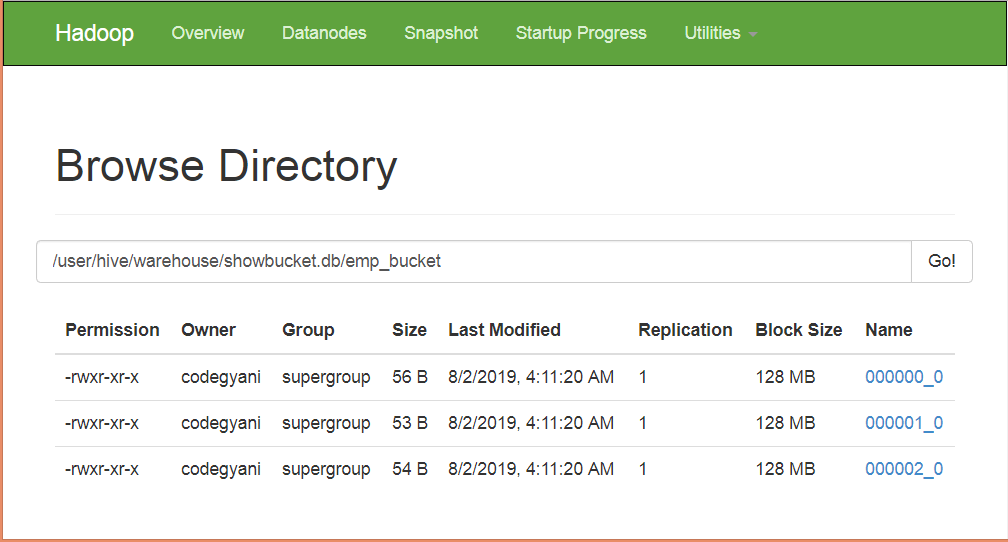 让我们检索存储区0的数据。
让我们检索存储区0的数据。