MapReduce 教程
MapReduce教程提供了MapReduce的基本和高级概念。我们的MapReduce教程是为初学者和专业人士设计的。
我们的MapReduce教程包括MapReduce的所有主题,例如MapReduce中的数据流,Map Reduce API,字数示例,字符数示例等。
什么是MapReduce?
MapReduce是一种数据处理工具,用于以分布式形式并行处理数据。它是在2004年根据Google发布的题为" MapReduce: 大型集群上的简化数据处理"的论文开发的。
MapReduce是一个范式,它包含两个阶段,即mapper阶段和mapper阶段。减速器阶段。在Mapper中,输入以键值对的形式给出。映射器的输出作为输入馈送到减速器。减速器仅在映射器结束后才运行。约简器也接受键值格式的输入,约简器的输出是最终输出。
Map Reduce的步骤
该映射以对的形式获取数据,并返回一个<key,value>对的列表。在这种情况下,键将不是唯一的。
使用Map的输出,排序和混洗由Hadoop体系结构应用。这种排序和混洗对这些<key,value>对列表起作用,并发出唯一键和与此唯一键<key,list(values)>相关的值列表。
sort和shuffle的输出发送到reducer阶段。 reducer在唯一键的值列表上执行已定义的功能,并且最终输出<key,value>将被存储/显示。
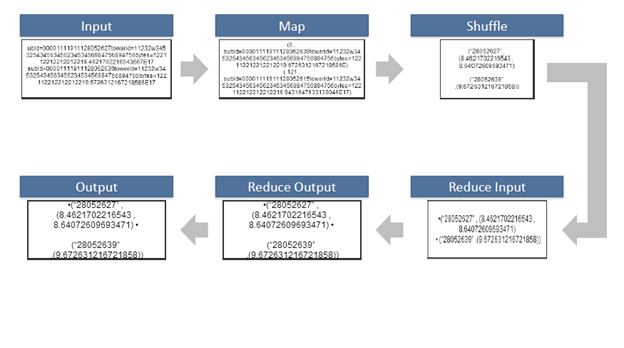
排序和混排
排序和混排发生在Mapper的输出上以及化简器之前。当Mapper任务完成时,结果将按键排序,如果有多个化简器,则将其分区,然后写入磁盘。使用每个Mapper
的输入,我们收集每个唯一键k2的所有值。混洗阶段以<k2,list(v2)>形式的输出作为输入发送给reducer阶段。
MapReduce的使用
它可用于各种应用程序,例如文档聚类,分布式排序和Web链接图反转。
它可用于基于模式的分布式搜索。
我们还可以在机器学习中使用MapReduce。
它被Google用来重新生成Google的万维网索引。
它可以用于多种计算环境中,例如多集群,多核和移动环境。
