HiveQL GROUP BY/HAVING
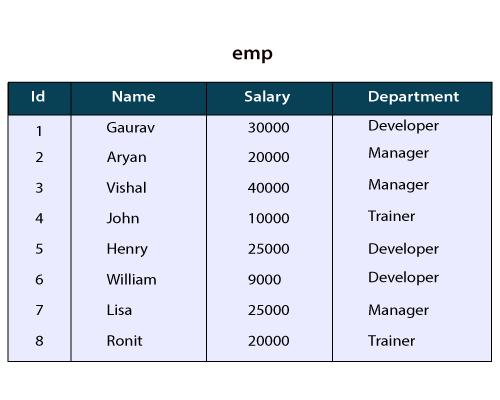
Hive查询语言提供了GROUP BY和HAVING子句,这些子句促进了与SQL中类似的功能。在这里,我们将在下表的记录上执行这些子句:
GROUP BY子句
HQL Group By 子句用于对来自多个记录的数据进行分组在一个或多个列上。它通常与聚合函数(例如SUM,COUNT,MIN,MAX和AVG)结合使用,以对每个组执行聚合。
Hive中GROUP BY子句的示例
让我们看一个示例,该示例根据部门对员工的工资进行汇总。
选择要在其中创建表的数据库。
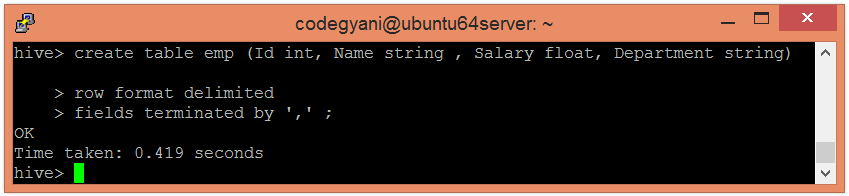
 现在,使用以下命令创建表:
现在,使用以下命令创建表:
hive> create table emp (Id int, Name string , Salary float, Department string)
row format delimited
fields terminated by ',' ;
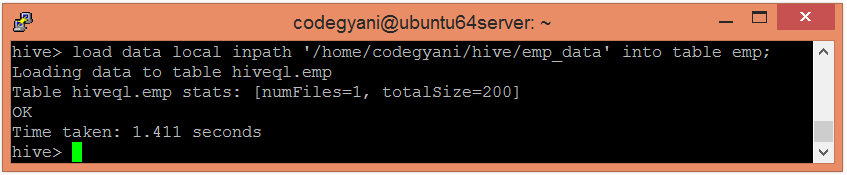
 将数据加载到表中。
将数据加载到表中。
hive> load data local inpath '/home/codegyani/hive/emp_data' into table emp;
 现在,使用以下命令明智地提取员工薪资部门的总和:
现在,使用以下命令明智地提取员工薪资部门的总和:
hive> select department, sum(salary) from emp group by department;
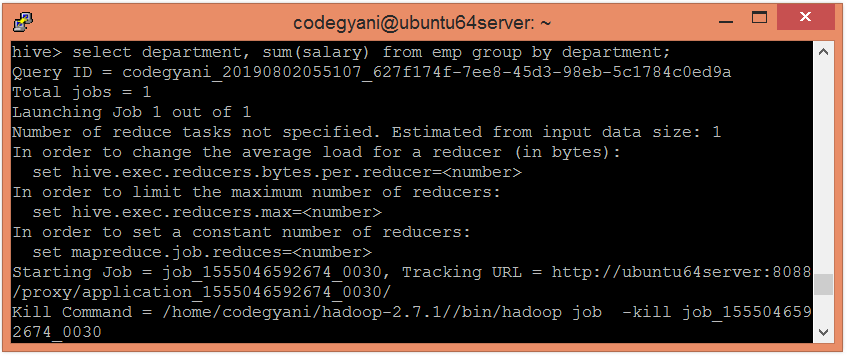
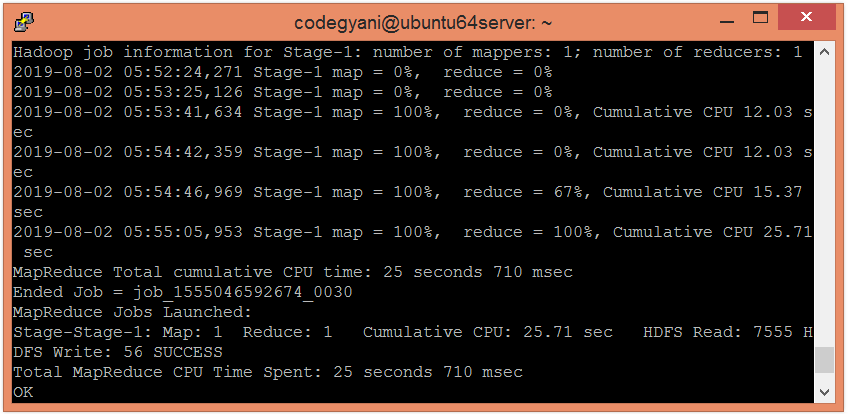

在这里,我们得到了所需的输出。
HAVING CLAUSE
HQL HAVING子句与 GROUP BY 子句一起使用。其目的是对GROUP BY子句产生的数据组施加约束。因此,它总是返回条件为 TRUE 的数据。
在Hive中包含子句的示例
在此示例中,我们根据部门提取员工的薪水总和,并使用HAVING子句对该薪水应用所需的约束。
让我们使用以下命令根据部门的薪水总和> = 35000来获取薪水总和:
hive> select department, sum(salary) from emp group by department having sum(salary)>=35000;
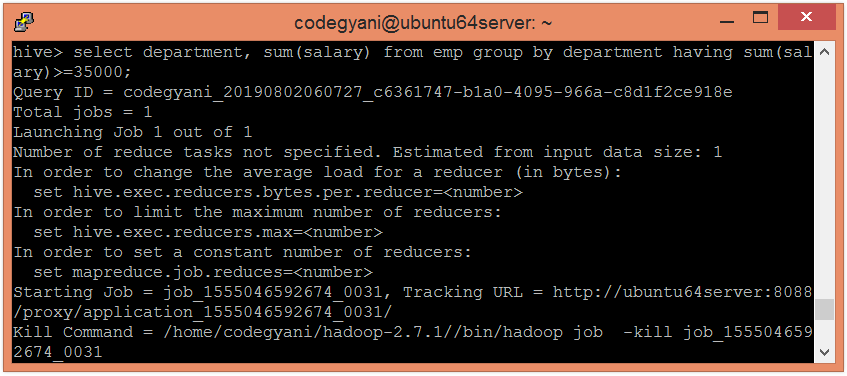
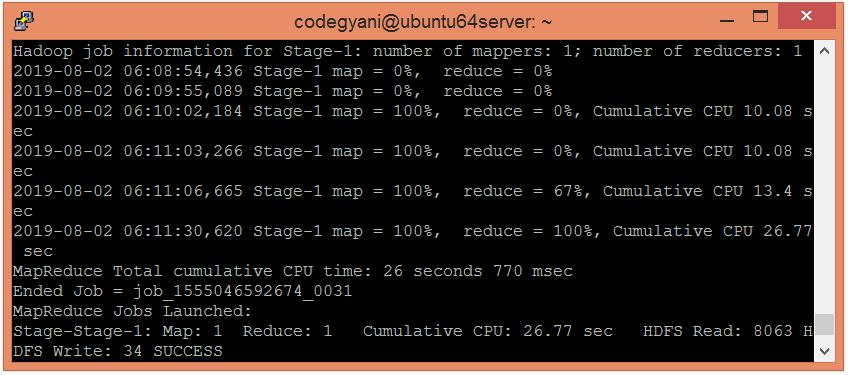
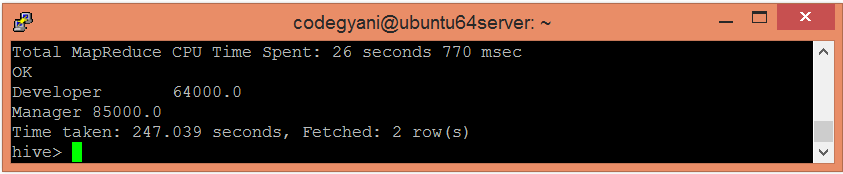
在这里,我们得到了所需的输出。

