什么是Hadoop
什么是Hadoop?
Hadoop是Apache的开源框架,用于存储过程和分析大量数据。 Hadoop是用Java编写的,不是OLAP(在线分析处理)。它用于批处理/脱机处理.Facebook,Yahoo,Google,Twitter,LinkedIn等使用它。而且,仅通过在集群中添加节点就可以扩展规模。
Hadoop模块
HDFS: : Hadoop分布式文件系统。 Google发表了论文GFS,并在此基础上开发了HDFS。它指出文件将被分解成块,并存储在分布式体系结构的节点中。
纱线: 另一种资源协商器用于作业调度和管理集群。
Map Reduce: : 这是一个框架,可帮助Java程序使用键值对对数据进行并行计算。 Map任务将输入数据转换为可在键值对中计算的数据集。 Map任务的输出被reduce任务消耗,然后out of reducer提供所需的结果。
Hadoop通用: 这些Java库用于启动Hadoop,并由其他Hadoop模块使用。
Hadoop体系结构
Hadoop体系结构是文件系统,MapReduce引擎和HDFS(Hadoop分布式文件系统)的软件包。 MapReduce引擎可以是MapReduce/MR1或YARN/MR2、
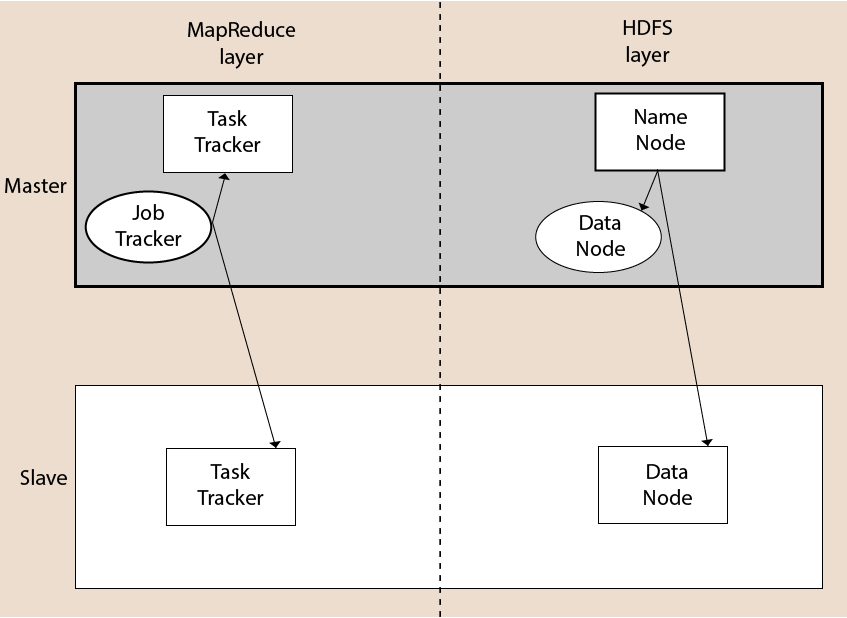
Hadoop集群由一个主节点和多个从节点组成。主节点包括Job Tracker,Task Tracker,NameNode和DataNode,而从节点包括DataNode和TaskTracker。
Hadoop分布式文件系统
Hadoop分布式文件系统(HDFS)是Hadoop的分布式文件系统。它包含一个主/从体系结构。这种体系结构由一个NameNode充当主角色,多个DataNode充当从角色。
NameNode和DataNode都具有足够的能力在商用机器上运行。 Java语言用于开发HDFS。因此,任何支持Java语言的机器都可以轻松运行NameNode和DataNode软件。
NameNode
这是HDFS群集中存在的单个主服务器。
由于它是一个单节点,因此可能成为单点故障的原因。
它通过执行打开,重命名和关闭文件之类的操作来管理文件系统名称空间。
它简化了系统的体系结构。
DataNode
HDFS群集包含多个DataNode。
每个DataNode包含多个数据块。
这些数据块用于存储数据。
DataNode负责读取和写入来自文件系统客户端的请求。
它根据NameNode的指令执行块创建,删除和复制。
作业跟踪器
Job Tracker的作用是从客户端接受MapReduce作业并使用NameNode处理数据。
作为响应,NameNode将元数据提供给Job Tracker。
任务跟踪器
它充当Job Tracker的从节点。
它从Job Tracker接收任务和代码,并将该代码应用于文件。此过程也可以称为Mapper。
MapReduce层
当客户端应用程序将MapReduce作业提交给Job Tracker时,MapReduce便存在了。作为响应,作业跟踪程序将请求发送到适当的任务跟踪程序。有时,TaskTracker失败或超时。在这种情况下,该工作的一部分将重新安排。
Hadoop的优势
快速: 在HDFS中,数据分布在群集中并被映射,这有助于更快地进行检索。即使是用于处理数据的工具也经常位于同一服务器上,从而减少了处理时间。它能够在数分钟内处理数TB的数据,在数小时内处理Peta的数据。
可扩展: 只需添加集群中的节点即可扩展Hadoop集群。
具有成本效益: Hadoop是开放源代码,并使用商品硬件存储数据,因此与传统的关系数据库管理系统相比,它确实具有成本效益。
可恢复故障: : HDFS具有可以通过网络复制数据的属性,因此,如果一个节点出现故障或其他网络故障,则Hadoop将获取另一份数据副本,用它。通常,数据会被复制三次,但是复制因子是可配置的。
Hadoop的历史
Hadoop由Doug Cutting和Mike Cafarella于2002年创立。其起源是Google出版的Google文件系统论文。
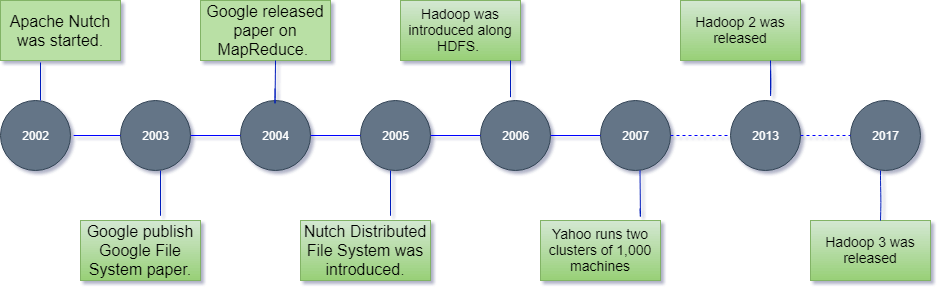
在以下步骤中,我们将重点放在Hadoop的历史上:-
2002年,Doug Cutting和Mike Cafarella开始从事一个项目,即 Apache Nutch。。这是一个开源Web爬虫软件项目。
在研究Apache Nutch时,他们正在处理大数据。为了存储该数据,他们必须花费大量成本,这成为该项目的结果。这个问题成为Hadoop出现的重要原因之一。
2003年,Google引入了一种称为GFS(Google文件系统)的文件系统。它是专有的分布式文件系统,旨在提供对数据的有效访问。
2004年,Google发布了有关Map Reduce的白皮书。该技术简化了大型集群上的数据处理。
2005年,Doug Cutting和Mike Cafarella推出了一种新的文件系统,称为NDFS(Nutch分布式文件系统)。此文件系统还包括Map reduce。
2006年,道格·切特(Doug Cutting)退出了Google,并加入了雅虎。在Nutch项目的基础上,Dough Cutting引入了一个新项目Hadoop,该项目的文件系统称为HDFS(Hadoop分布式文件系统)。今年发布了Hadoop第一版0.1.0。
Doug Cutting以儿子的玩具大象命名了他的项目Hadoop。
2007年,雅虎运行着两个由1000台计算机组成的集群。
2008年,Hadoop成为最快的系统,可在209秒内对900个节点集群上的1 TB数据进行排序。
2013年,发布了Hadoop 2.2、
2017年,发布了Hadoop 3.0。
| 年份 |
事件 |
| 2003 |
Google发布了文件Google File System(GFS)。 |
| 2004 |
Google在Map Reduce上发布了白皮书。 |
| 2006 |
引入了Hadoop
发布Hadoop 0.1.0。 |
| 2007 |
Yahoo运行着两个由1000台计算机组成的集群。
Hadoop包含HBase。 |
| 2008 |
YARN JIRA发布
Hadoop成为最快的系统,可在209秒内对900节点群集上的1 TB数据进行排序。
Yahoo群集每天加载10 TB数据。
Cloudera作为Hadoop发行商成立。 |
| 2009 |
雅虎运行着17个集群,共24,000台计算机。
Hadoop具有足够的能力来分类PB。
MapReduce和HDFS成为单独的子项目。 |
| 2010 |
Hadoop添加了对Kerberos的支持。
Hadoop可运行4,000个节点,容量为40 PB。
Apache Hive和Pig发行了。 |
| 2011 |
Apache Zookeeper发布。
雅虎拥有42,000个Hadoop节点和数百PB的存储空间。 |
| 2012 |
Apache Hadoop 1.0版本已发布。 |
| 2013 |
Apache Hadoop 2.2版本发布。 |
| 2014 |
Apache Hadoop 2.6版本已发布。 |
| 2015 |
Apache Hadoop 2.7版本已发布。 |
| 2017 |
Apache Hadoop 3.0版本已发布。 |
| 2018 |
Apache Hadoop 3.1版本已发布。 |

