希尔排序
希尔 排序是一种高效的排序算法,基于插入排序算法。如果较小的值在最右边并且必须移动到最左边,则该算法避免了插入排序中的大移位。
该算法对分布广泛的元素使用插入排序,首先对它们进行排序,然后对间隔较小的元素进行排序。这个间距被称为
interval。这个区间是根据 Knuth 的公式计算的-
克努特公式
h = h * 3 + 1
where −
h is interval with initial value 1
该算法对于中等规模的数据集非常有效,因为该算法的平均复杂度和最坏情况复杂度取决于间隙序列,最著名的是 Ο(n),其中 n 是项目数。而最坏情况的空间复杂度是O(n)。
Shell 排序如何工作?
让我们考虑以下示例,以了解 shell 排序的工作原理。我们采用与之前示例中使用的相同的数组。为了我们的示例和易于理解,我们采用 4 的间隔。对位于 4 位置间隔的所有值创建一个虚拟子列表。这里这些值是 {35, 14}, {33, 19}, {42, 27} 和 {10, 44}
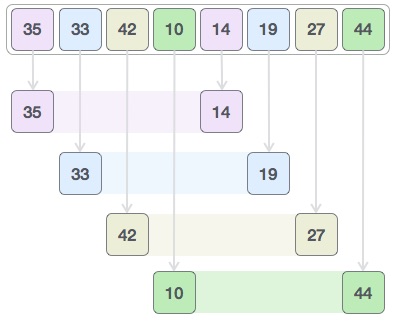
我们比较每个子列表中的值并在原始数组中交换它们(如果需要)。在这一步之后,新的数组应该是这样的-

然后,我们取区间 1,这个间隙生成两个子列表-{14, 27, 35, 42}, {19, 10, 33, 44}
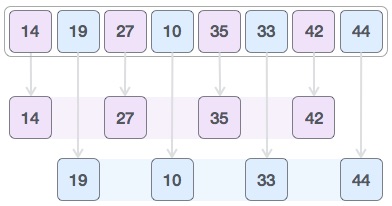
如果需要,我们会比较和交换原始数组中的值。在这一步之后,数组应该是这样的-

最后,我们使用值 1 的区间对数组的其余部分进行排序。Shell 排序使用插入排序对数组进行排序。
以下是一步一步的描述-
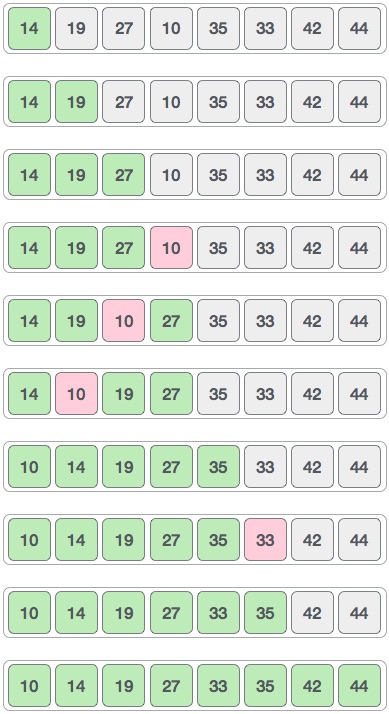
我们看到它只需要四次交换即可对数组的其余部分进行排序。
算法
以下是shell排序的算法。
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sorted
伪代码
以下是shell排序的伪代码。
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval-1 && A[inner-interval] >= valueToInsert do:
A[inner] = A[inner-interval]
inner = inner-interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval-1) /3;
end while
end procedure

