二叉树
树表示由边连接的节点。我们将具体讨论二叉树或二叉搜索树。
二叉树是一种用于数据存储的特殊数据结构。二叉树有一个特殊的条件,即每个节点最多可以有两个孩子。二叉树同时具有有序数组和链表的优点,因为搜索和排序数组一样快,插入或删除操作和链表一样快。
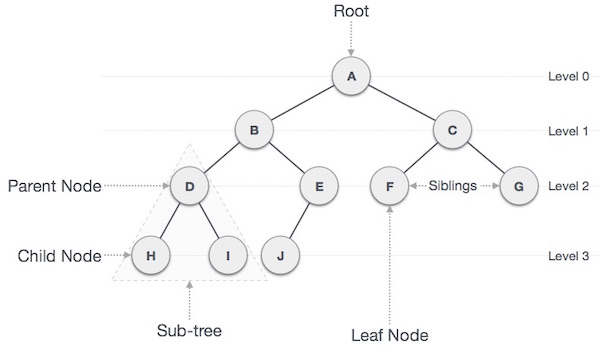
重要条款
以下是关于树的重要术语。
Path-路径是指沿树边缘的节点序列。
Root-树顶部的节点称为根。每棵树只有一个根,并且从根节点到任何节点都有一条路径。
Parent-除根节点外的任何节点都有一个向上的边缘到称为父节点的节点。
Child-给定节点下方由其边缘向下连接的节点称为其子节点。
Leaf-没有任何子节点的节点称为叶节点。
Subtree-子树代表一个节点的后代。
Visiting-访问是指当控制在节点上时检查节点的值。
Traversing-遍历意味着以特定顺序通过节点。
Levels-节点的级别表示节点的生成。如果根节点处于 0 级,则其下一个子节点处于 1 级,其孙节点处于 2 级,依此类推。
keys-键表示节点的值,根据该值对节点执行搜索操作。
二叉搜索树表示
二叉搜索树表现出一种特殊的行为。节点的左子节点的值必须小于其父节点的值,而节点的右子节点的值必须大于其父节点的值。
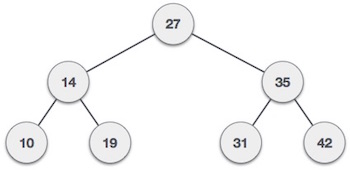
我们将使用节点对象实现树并通过引用连接它们。
树节点
编写树节点的代码类似于下面给出的代码。它有一个数据部分和对其左右子节点的引用。
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};
在树中,所有节点共享共同的结构。
BST 基本操作
可以对二叉搜索树数据结构执行的基本操作如下-
Insert-在树中插入元素/创建树。
Search-搜索树中的元素。
Preorder Traversal-以预序方式遍历树。
Inorder Traversal-以中序方式遍历树。
Postorder Traversal-以后序方式遍历树。
我们将在本章中学习创建(插入)树结构并在树中搜索数据项。我们将在下一章学习遍历树的方法。
插入操作
第一次插入创建树。之后,每当要插入一个元素时,首先要找到它的正确位置。从根节点开始搜索,如果数据小于key值,则在左子树中搜索空位置,插入数据。否则,在右子树中搜索空位置并插入数据。
算法
if root is null
then create root node
return
if root exists then
compare the data with node.data
while until insertion position is located
if data is greater than node.data
goto right subtree
else
goto left subtree
endwhile
insert data
end if
实施
插入函数的实现应该是这样的-
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = null;
tempNode->rightChild = null;
//if tree is empty, create root node
if(root == null) {
root = tempNode;
} else {
current = root;
parent = null;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == null) {
parent->leftChild = tempNode;
return;
}
}
//go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == null) {
parent->rightChild = tempNode;
return;
}
}
}
}
}
搜索操作
每当要查找一个元素时,从根节点开始查找,如果数据小于键值,则在左子树中查找该元素。否则,在右子树中搜索元素。对每个节点遵循相同的算法。
算法
if root.data is equal to search.data
return root
else
while data not found
if data is greater than node.data
goto right subtree
else
goto left subtree
if data found
return node
endwhile
return data not found
end if
这个算法的实现应该是这样的。
struct node* search(int data) {
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data) {
if(current != null)
printf("%d ",current->data);
//go to left tree
if(current->data > data) {
current = current->leftChild;
}
//else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == null) {
return NULL;
}
return current;
}
}
二叉树遍历
遍历是访问树的所有节点的过程,也可以打印它们的值。因为,所有节点都是通过边(链接)连接的,所以我们总是从根(头)节点开始。也就是说,我们不能随机访问树中的节点。我们使用三种方式遍历树-
顺序遍历
前序遍历
后序遍历
通常,我们遍历树以搜索或定位树中的给定项或键,或者打印它包含的所有值。
顺序遍历
在这种遍历方法中,首先访问左子树,然后是根,然后是右子树。我们应该永远记住,每个节点都可能代表一个子树本身。
如果
按顺序遍历二叉树,输出将产生按升序排序的键值。
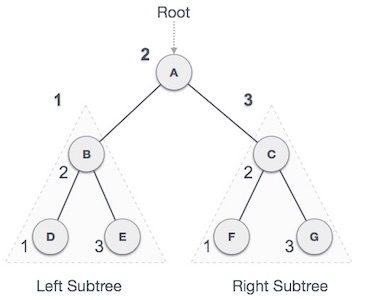
我们从
A开始,依次遍历,移动到它的左子树
B。
B 也是按顺序遍历的。该过程一直持续到所有节点都被访问为止。这棵树的中序遍历的输出将是-
D → B → E → A → F → C → G
算法
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.
前序遍历
在这种遍历方法中,首先访问根节点,然后访问左子树,最后访问右子树。
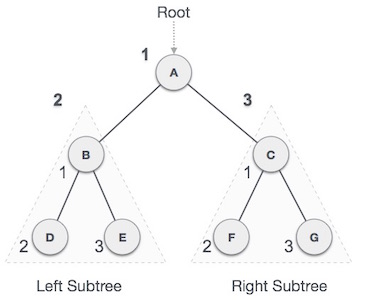
我们从
A开始,经过前序遍历,我们首先访问
A本身,然后移动到它的左子树
B。
B 也是预购遍历的。该过程一直持续到所有节点都被访问为止。这棵树的前序遍历的输出将是-
A → B → D → E → C → F → G
算法
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.
后序遍历
在这种遍历方法中,根节点是最后访问的,因此得名。首先我们遍历左子树,然后是右子树,最后是根节点。
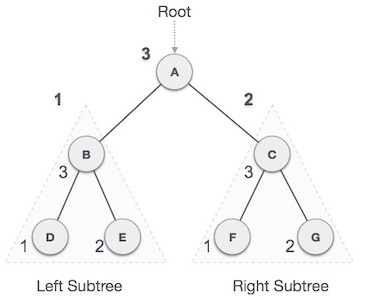
我们从
A开始,经过后序遍历,我们首先访问左子树
B。
B 也是后序遍历的。该过程一直持续到所有节点都被访问为止。这棵树的后序遍历的输出将是-
D → E → B → F → G → C → A
算法
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.
二叉树详细讲解

